I have a pandas df something like this:
color pct days text
1 red 5 7 good
2 red 10 30 good
3 red 11 60 bad
4 blue 6 7 bad
5 blue 15 30 good
6 blue 21 60 bad
7 yellow 2 7 good
8 yellow 5 30 bad
9 yellow 7 60 bad
So basically, for each color, I have percentage values for 7 days, 30 days and 60 days. Please note that these are not always in correct order as I gave in example above. My task now is to look at the change in percentage for each color between the consecutive days values and if the change is greater or equal to 5%, then write in column "text" as "NA". Text in days 7 category is default and cannot be overwritten.
Desired result:
color pct days text
1 red 5 7 good
2 red 10 30 NA
3 red 11 60 bad
4 blue 6 7 bad
5 blue 15 30 NA
6 blue 21 60 NA
7 yellow 2 7 good
8 yellow 5 30 bad
9 yellow 7 60 bad
I am able to achieve this by a very very long process that I am very sure is not efficient. I am sure there is a much better way of doing this, but I am new to python, so struggling. Can someone please help me with this? Many thanks in advance
CodePudding user response:
In the code below I'm reading your example table into a pandas dataframe using io, you don't need to do this, you already have your pandas table.
import pandas as pd
import io
df = pd.read_csv(io.StringIO(
""" color pct days text
1 red 5 7 good
2 red 10 30 good
3 red 11 60 bad
4 blue 6 7 bad
5 blue 15 30 good
6 blue 21 60 bad
7 yellow 2 7 good
8 yellow 5 30 bad
9 yellow 7 60 bad"""
),delim_whitespace=True)
not_seven_rows = df['days'].ne(7)
good_rows = df['pct'].lt(5)
#Set the rows which are < 5 and not 7 days to be 'good'
df.loc[good_rows & not_seven_rows, 'text'] = 'good'
#Set the rows which are >= 5 and not 7 days to be 'NA'
df.loc[(~good_rows) & not_seven_rows, 'text'] = 'NA'
df
Output
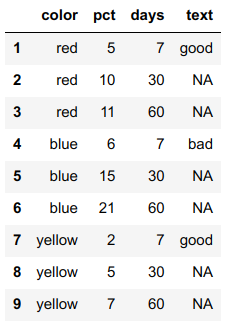
CodePudding user response:
A variation on a (now-deleted) suggested answer as comment:
# ensure numeric data
df['pct'] = pd.to_numeric(df['pct'], errors='coerce')
df['days'] = pd.to_numeric(df['days'], errors='coerce')
# update in place
df.loc[df.sort_values(['color','days'])
.groupby('color')['pct']
.diff().ge(5), 'text'] = 'NA'
Output:
color pct days text
1 red 5 7 good
2 red 10 30 NA
3 red 11 60 bad
4 blue 6 7 bad
5 blue 15 30 NA
6 blue 21 60 NA
7 yellow 2 7 good
8 yellow 5 30 bad
9 yellow 7 60 bad