I am trying to use rolling().sum() to create a dataframe with 2-month rolling sums within each 'type'. Here's what my data looks like:
import pandas as pd
df = pd.DataFrame({'type': ['A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'C', 'C', 'C', 'C'],
'date': ['2022-01-01', '2022-02-01', '2022-03-01', '2022-04-01',
'2022-01-01', '2022-02-01', '2022-03-01', '2022-04-01',
'2022-01-01', '2022-02-01', '2022-03-01', '2022-04-01'],
'value': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]})
and here is the expected result:
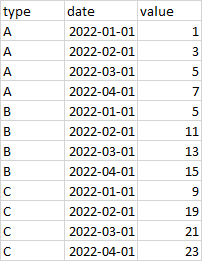
and here is what I have tried (unsuccessfully):
rolling_sum = df.groupby(['date', 'type']).rolling(2).sum().reset_index()
CodePudding user response:
Here's a way to do it:
rolling_sum = (
df.assign(value=df.groupby(['type'])['value']
.rolling(2, min_periods=1).sum().reset_index()['value'])
)
Output:
type date value
0 A 2022-01-01 1.0
1 A 2022-02-01 3.0
2 A 2022-03-01 5.0
3 A 2022-04-01 7.0
4 B 2022-01-01 5.0
5 B 2022-02-01 11.0
6 B 2022-03-01 13.0
7 B 2022-04-01 15.0
8 C 2022-01-01 9.0
9 C 2022-02-01 19.0
10 C 2022-03-01 21.0
11 C 2022-04-01 23.0
Explanation:
- Use
groupby()only ontype(withoutdate) so that all dates are in the group for a giventype - the
min_periodsargument ensuresrollingworks even for the first row where 2 periods are not available - Use
assign()to update thevaluecolumn using index alignment.
CodePudding user response:
Answer
The below code does the work.
rolling_sum = df.groupby(['type']).rolling(2).sum()