How to make wordcloud plot based on two columns values? I have a dataframe as follows:
Name <- c("Jon", "Bill", "Maria", "Ben", "Tina", "Vikram", "Ramesh", "Luther")
Age <- c(23, 41, 32, 58, 26, 41, 32, 58)
Pval <- c(0.01, 0.06, 0.001, 0.002, 0.025, 0.05, 0.01, 0.0002)
df <- data.frame(Name, Age, Pval)
I want to make wordcloud plot for df$Name based on values in df$Age and df$Pval. I used following code:
library("tm")
library("SnowballC")
library("wordcloud")
library("wordcloud2")
library("RColorBrewer")
set.seed(1234)
wordcloud(words = df$Name, freq = df$Age, min.freq = 1,
max.words=10, random.order=FALSE, rot.per=0.35,
colors=brewer.pal(8, "Dark2"))
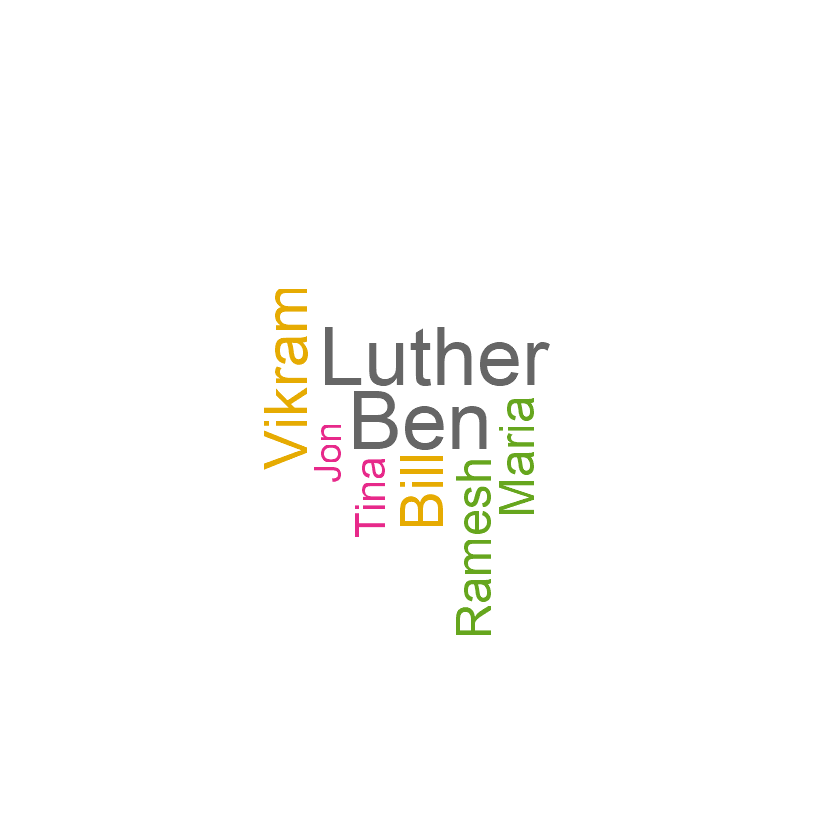
Here Luther & Ben are of same size, but I need to make Luther to be slightly bigger than Ben as it has lower Pval.
CodePudding user response:
A quick fix workaround:
library("dplyr")
library("scales")
library("wordcloud")
library("RColorBrewer")
Name <- c("Jon", "Bill", "Maria", "Ben", "Tina", "Vikram", "Ramesh", "Luther")
Age <- c(23, 41, 32, 58, 26, 41, 32, 58)
Pval <- c(0.01, 0.06, 0.001, 0.002, 0.025, 0.05, 0.01, 0.0002)
df <- data.frame(Name, Age, Pval)
df <- df %>%
group_by(Age) %>%
mutate(rank = rank(Pval)) %>% #rank pvalue by age
mutate(weight = scales::rescale(rank/max(rank), to=c(0,1))) %>%
#this is just to make sure that we don't add more than one to the mix
mutate(weight = Age (1-weight) ) #because rank is inversed
#the final thing adds 0.5 if there is not anyone with the same age and 1 if
#there is someone else but you have a smaller p-val (it also should work if
# there is more than 2 person with the same age)
set.seed(1234)
wordcloud(words = df$Name, freq = df$weight, min.freq = 1,
max.words=10, random.order=FALSE, rot.per=0.35,
colors=brewer.pal(8, "Dark2"))
Fun and interesting question btw