I am trying to extract the download syllabus link from this website-
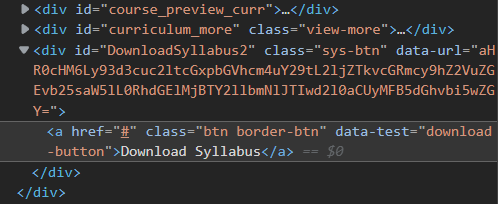
the link is hidden with '#' in page source.
So I am not sure, how to extract the links. I know that I won't be able to extract using xpath or css. Can someone help me?
CodePudding user response:
In this particular case,
The URL link is base64 encoded in the div with id = "DownloadSyllabus2", on its data-url attribute (right above the a href you are mentioning):
aHR0cHM6Ly93d3cuc2ltcGxpbGVhcm4uY29tL2ljZTkvcGRmcy9hZ2VuZGEvb25saW5lL0RhdGElMjBTY2llbmNlJTIwd2l0aCUyMFB5dGhvbi5wZGY=
You need to decode it using base64 and you will get the desired url: https://www.simplilearn.com/ice9/pdfs/agenda/online/Data Science with Python.pdf
This is not a magic solution for all cases like this, but it works for this website and is the best solution here.
So, Data extraction is not always about the solutions, but to be able to reverse engineer the website logic.
Happy Scraping :)