I would like to get common elements in two given strings such that duplicates will be taken care of. It means that if a letter occurs 3 times in the first string and 2 times in the second one, then in the common string it has to occur 2 times. The length of the two strings may be different. eg
s1 = 'aebcdee'
s2 = 'aaeedfskm'
common = 'aeed'
I can not use the intersection between two sets. What would be the easiest way to find the result 'common' ? Thanks.
CodePudding user response:
Well there are multiple ways in which you can get the desired result. For me the simplest algorithm to get the answer would be:
- Define an empty
dict. Liked = {} - Iterate through each character of the first string:
if the character is not present in the dictionary, add the character to the dictionary.
else increment the count of character in the dictionary. - Create a variable as
common = "" - Iterate through the second string characters, if the count of that character in the dictionary above is greater than 0: decrement its value and add this character to
common - Do whatever you want to do with the
common
The complete code for this problem:
s1 = 'aebcdee'
s2 = 'aaeedfskm'
d = {}
for c in s1:
if c in d:
d[c] = 1
else:
d[c] = 1
common = ""
for c in s2:
if c in d and d[c] > 0:
common = c
d[c] -= 1
print(common)
CodePudding user response:
You can use two arrays (length 26). One array is for the 1st string and 2nd array is for the second string.
Initialize both the arrays to 0.
The 1st array's 0th index denotes the number of "a" in 1st string, 1st index denotes number of "b" in 1st string, similarly till - 25th index denotes number of "z" in 1st string.
Similarly, you can create an array for the second string and store the count of each alphabet in their corresponding index.
s1 = 'aebcdee' s2 = 'aaeedfs' Below is the array example for the above s1 and s2 values
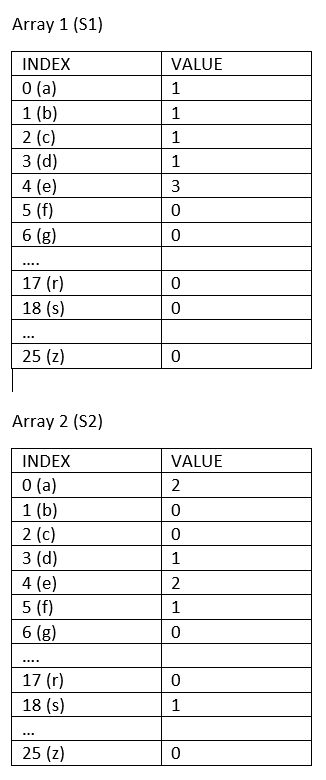
Now you can run through the 1st String s1 = 'aebcdee'
for each alphabet find the
K = minimum of ( [ count(alphabet) in Array 1 ], [ count(alphabet) in Array 2 ] )
and print that alphabet K times.
then make that alphabet count to 0 in both the arrays. (Because if you dint make it zero, then our algo might print the same alphabet again if it comes in the future).
Complexity - O( length(S1) )
Note - You can also run through the string having a minimum length to reduce the complexity. In that case Complexity - O( minimum [ length(S1), length(S2) ] )
Please let me know if you want the implementation of this.
CodePudding user response:
you can use collection.Counter and count each char in two string and if each char exist in two string using min of list and create a new string by join of them.
from collections import Counter, defaultdict
from itertools import zip_longest
s1 = 'aebcdee'
s2 = 'aaeedfskm'
# Create a dictionary the value is 'list' and can append char in each 'list'
res = defaultdict(list)
# get count of each char
cnt1 = Counter(s1) # -> {'e': 3, 'a': 1, 'b': 1, 'c': 1, 'd': 1}
cnt2 = Counter(s2) # -> {'a': 2, 'e': 2, 'd': 1, 'f': 1, 's': 1, 'k': 1, 'm': 1}
# for appending chars in one step, we can zip count of chars in two strings,
# so Because maybe two string have different length, we can use 'itertools. zip_longest'
for a,b in zip_longest(cnt1 , cnt2):
# list(zip_longest(cnt1 , cnt2)) -> [('a', 'a'), ('e', 'e'), ('b', 'd'),
# ('c', 'f'), ('d', 's'), (None, 'k'),
# (None, 'm')]
# Because maybe we have 'none', before 'append' we need to check 'a' and 'b' don't be 'none'
if a: res[a].append(cnt1[a])
if b: res[b].append(cnt2[b])
# res -> {'a': [1, 2], 'e': [3, 2], 'b': [1], 'd': [1, 1], 'c': [1], 'f': [1], 's': [1], 'k': [1], 'm': [1]}
# If the length 'list' of each char is larger than one so this char is duplicated and we repeat this char in the result base min of each char in the 'list' of count char of two strings.
out = ''.join(k* min(v) for k,v in res.items() if len(v)>1)
print(out)
# aeed
We can use this approach for multiple string, like three strings.
s1 = 'aebcdee'
s2 = 'aaeedfskm'
s3 = 'aaeeezzxx'
res = defaultdict(list)
cnt1 = Counter(s1)
cnt2 = Counter(s2)
cnt3 = Counter(s3)
for a,b,c in zip_longest(cnt1 , cnt2, cnt3):
if a: res[a].append(cnt1[a])
if b: res[b].append(cnt2[b])
if c: res[c].append(cnt3[c])
out = ''.join(k* min(v) for k,v in res.items() if len(v)>1)
print(out)
# aeed
CodePudding user response:
s1="ckglter"
s2="ancjkle"
final_list=[]
if(len(s1)<len(s2)):
for i in s1:
if(i in s2):
final_list.append(i)
else:
for i in s2:
if(i in s1):
final_list.append(i)
print(final_list)
you can also do it like this also, just iterate through both the string using for loop and append the common character into the empty list