The below condition needs to be applied on RANK and RANKA columns
Input table:
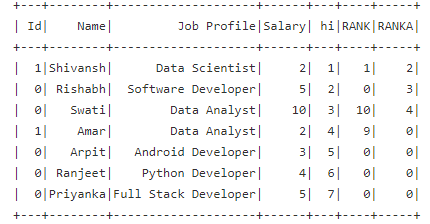
Condition for RANK column:
IF RANK == 0 : then RANK= previous RANK value 1 ;
else : RANK=RANK
Condition for RANKA column:
- IF RANKA == 0 : then RANKA= previous RANKA value current row Salary value;
- else : RANKA=RANKA
Below is a piece of code that I tried.
I have created dummy columns named RANK_new and RANKA_new for storing the desired outputs of RANK and RANKA columns after applying conditions. And then once I get the correct values I can replace the RANK and RANKA column with those dummy columns.
# importing necessary libraries
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.window import Window
from pyspark.sql.functions import when, col
# function to create new SparkSession
from pyspark.sql.functions import lit
from pyspark.sql.functions import lag,lead
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("employee_profile.com") \
.getOrCreate()
return spk
def create_df(spark, data, schema):
df1 = spark.createDataFrame(data, schema)
return df1
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [(1, "Shivansh", "Data Scientist", 2,1,1,2),
(0, "Rishabh", "Software Developer", 5,2,0,3),
(0, "Swati", "Data Analyst", 10,3,10,4),
(1, "Amar", "Data Analyst", 2,4,9,0),
(0, "Arpit", "Android Developer", 3,5,0,0),
(0, "Ranjeet", "Python Developer", 4,6,0,0),
(0, "Priyanka", "Full Stack Developer",5,7,0,0)]
schema = ["Id", "Name", "Job Profile", "Salary",'hi','RANK','RANKA']
# calling function to create dataframe
dff = create_df(spark, input_data, schema)
# Below 3 lines for RANK
df1=dff.repartition(1)
df2 = df1.withColumn('RANK_new', when(col('RANK') == 0,lag(col('RANK') lit(1)).over(Window.orderBy(col('hi')))).otherwise(col('RANK')))
df2 = df2.withColumn('RANK_new', when((col('RANK') == 0) & (lag(col('RANK')).over(Window.orderBy(col('hi'))) == 0) ,lag(col('RANK_new') lit(1)).over(Window.orderBy(col('hi')))).otherwise(col('RANK_new')))
#Below line for RANKA
df2=df2.withColumn('RANKA_new', when(col('RANKA') == 0, lag(col("RANKA")).over(Window.orderBy("hi")) col("Salary")).otherwise(col('RANKA')))
df2.show()
The issue with this code is that the lag function is not taking the updated values of the previous rows. This can be done with a for loop but since my data is so huge, I need a solution without for loop.
Below is the desired output:
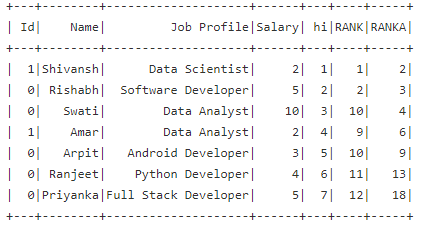
Below is a summarized picture to show the Output I got and the desired output.
RANK_new, RANKA_new --> These are the output I got for RANK and RANKA columns after I applied the above code
RANK_desired, RANKA-desired ---> This is what is expected to be produced.

CodePudding user response:
You can first create groups for partitioning for both, RANK and RANKA. Then using sum inside partitions should work.
Input
from pyspark.sql import functions as F, Window as W
input_data = [(1, "Shivansh", "Data Scientist", 2,1,1,2),
(0, "Rishabh", "Software Developer", 5,2,0,3),
(0, "Swati", "Data Analyst", 10,3,10,4),
(1, "Amar", "Data Analyst", 2,4,9,0),
(0, "Arpit", "Android Developer", 3,5,0,0),
(0, "Ranjeet", "Python Developer", 4,6,0,0),
(0, "Priyanka", "Full Stack Developer",5,7,0,0)]
schema = ["Id", "Name", "Job Profile", "Salary",'hi','RANK','RANKA']
dff = spark.createDataFrame(input_data, schema)
Script:
w0 = W.orderBy('hi')
rank_grp = F.when(F.col('RANK') != 0, 1).otherwise(0)
dff = dff.withColumn('RANK_grp', F.sum(rank_grp).over(w0))
w1 = W.partitionBy('RANK_grp').orderBy('hi')
ranka_grp = F.when(F.col('RANKA') != 0, 1).otherwise(0)
dff = dff.withColumn('RANKA_grp', F.sum(ranka_grp).over(w0))
w2 = W.partitionBy('RANKA_grp').orderBy('hi')
dff = (dff
.withColumn('RANK_new', F.sum(F.when(F.col('RANK') == 0, 1).otherwise(F.col('RANK'))).over(w1))
.withColumn('RANKA_new', F.sum(F.when(F.col('RANKA') == 0, F.col('Salary')).otherwise(F.col('RANKA'))).over(w2))
.drop('RANK_grp', 'RANKA_grp')
)
dff.show()
# --- -------- -------------------- ------ --- ---- ----- -------- ---------
# | Id| Name| Job Profile|Salary| hi|RANK|RANKA|RANK_new|RANKA_new|
# --- -------- -------------------- ------ --- ---- ----- -------- ---------
# | 1|Shivansh| Data Scientist| 2| 1| 1| 2| 1| 2|
# | 0| Rishabh| Software Developer| 5| 2| 0| 3| 2| 3|
# | 0| Swati| Data Analyst| 10| 3| 10| 4| 10| 4|
# | 1| Amar| Data Analyst| 2| 4| 9| 0| 9| 6|
# | 0| Arpit| Android Developer| 3| 5| 0| 0| 10| 9|
# | 0| Ranjeet| Python Developer| 4| 6| 0| 0| 11| 13|
# | 0|Priyanka|Full Stack Developer| 5| 7| 0| 0| 12| 18|
# --- -------- -------------------- ------ --- ---- ----- -------- ---------