I want to create a dictionary with data from .csv file/files
I want to iterate through .csv files and use the first row of the .csv file as keys and third row of .csv file as values.
My code so far:
import pandas as pd
import collections
import operator
import functools
import os
import csv
import glob
root = "C:\\Users\\Public\\DiplomskaNaloga\\anomaly_count"
slovar_list = list()
for file in glob.glob(os.path.join(root, '*.csv')):
df = pd.read_csv(file, encoding = 'cp1252')
slovar = df.to_dict()
slovar_list.append(slovar)
res = dict(functools.reduce(operator.add,
map(collections.Counter, napake_list)))
I want a dictionary created as explained above. I will append each created dictionary to a list to create a list of dictionaries and then add the values of same keys as that is what I need as an output.
The command df.to_dict() doesn't work for me or I am just not experienced enough to understand the doc string on how to set it up to work for me
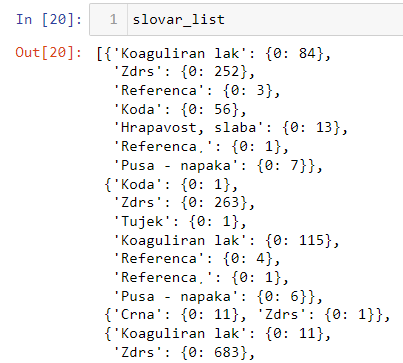
These zeros are from the second row which is empty. I dont need that.
CodePudding user response:
These zeros are NOT values from empty row(s) but indexes (number of row).
You should select single row using .iloc[] - but for your example output you should rather use index 0 instead of index 2 because it seems it skiped empty rows.
df.iloc[0].to_dict()
Minimal working example:
import pandas as pd
data = {
'Column X': ['A','B','C'],
'Column Y': ['D','E','F'],
'Column Z': ['G','H','I']
}
df = pd.DataFrame(data)
print('--- df ---')
print(df)
print('--- all rows ---')
print(df.to_dict())
print('--- one row ---')
print(df.iloc[2].to_dict())
Result:
--- df ---
Column X Column Y Column Z
0 A D G
1 B E H
2 C F I
--- all rows ---
{'Column X': {0: 'A', 1: 'B', 2: 'C'}, 'Column Y': {0: 'D', 1: 'E', 2: 'F'}, 'Column Z': {0: 'G', 1: 'H', 2: 'I'}}
--- one row ---
{'Column X': 'C', 'Column Y': 'F', 'Column Z': 'I'}