I have two csv files, each of which has two columns. File A is the master file which contains the order of the items, which is important. File B has some (but not all) updated information that needs to replace the old information in file A.
How do I replace the old values in column 2 of file A with the new values from column 2 of file B, but only where the values in column 1 are duplicates?
For example:
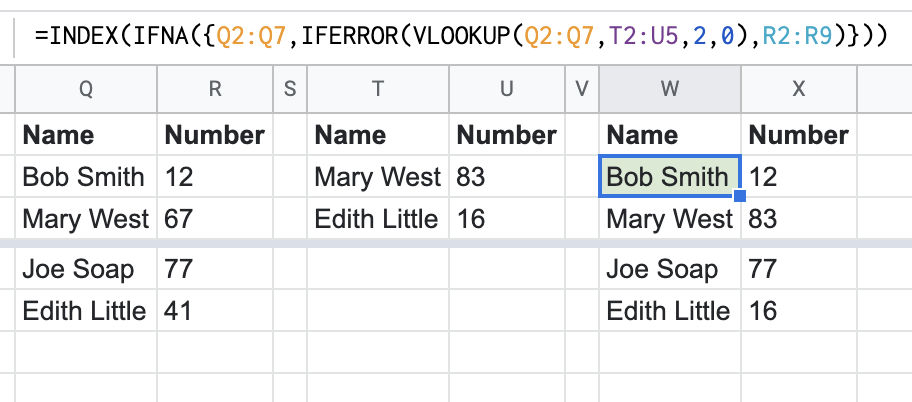
File A
| Name | Number |
|---|---|
| Bob Smith | 12 |
| Mary West | 67 |
| Joe Soap | 77 |
| Edith Little | 41 |
File B
| Name | Number |
|---|---|
| Mary West | 83 |
| Edith Little | 16 |
Desired result
| Name | Number |
|---|---|
| Bob Smith | 12 |
| Mary West | 83 |
| Joe Soap | 77 |
| Edith Little | 16 |
I feel like there should be a simple solution to this that I'm just missing, but I haven't had any luck with searching for a method.
Edit: I attempted to solve the problem using replace duplicates in google sheets, which resulted in the correct values, but the order was lost. I ran up against the same problem using Sublime Text in that I can keep the new values quite easily, but I can't seem to find a way to keep them in the position of the old values.
CodePudding user response:
Try the following
=INDEX(IFNA({Q2:Q7,IFERROR(VLOOKUP(Q2:Q7,T2:U5,2,0),R2:R9)}))
(Do adjust the formula according to your ranges and locale)