I have the next DataFrame:
a = [{'id': 1, 'name': 'AAA', 'pn':"[{'code_1': 'green'}, {'code_2': 'link'}, {'code_3': '10'}]"}, {'id': 2, 'name': 'BBB', 'pn': "[{'code_1': 'blue'}, {'code_2': 'link'}, {'code_3': '15'}]"}]
df = pd.DataFrame(a)
print(df)

I need to create two new columns and for example new column df['color'] = ..., new column df['link'] = ... and it should be like this, thanks:
CodePudding user response:
You could do this :
import ast
df['color'] = df.pn.map(lambda x: ast.literal_eval(x)[0])
df['link'] = df.pn.map(lambda x: ast.literal_eval(x)[1])
ast.literal_eval is used to convert the string into an actual python list and then we select the element we want :)
Have a nice day,
Gabriel
CodePudding user response:
Here's a way to do what you're asking:
df2 = ( df.assign(
pn=df.pn.apply(eval)).explode('pn').pn.astype(str)
.str.extract("'([^']*)'[^']*'([^']*)'") )
df2[0] = df2[0].map({'code_1':'color', 'code_2':'link', 'code_3':'code_3'})
df2 = df2.pivot(columns=[0])
df2.columns = df2.columns.droplevel(None)
df2 = ( df2.drop(columns='code_3').assign(
color = df2.color.map(lambda x: "{" f"'code_1': '{x}'" "}"),
link = df2.link.map(lambda x: "{" f"'code_2': '{x}'" "}")) )
df2 = pd.concat([df[['id','name']], df2], axis = 1)
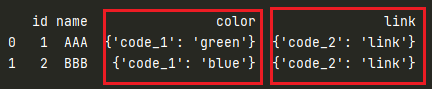
Output:
id name color link
0 1 AAA {'code_1': 'green'} {'code_2': 'link'}
1 2 BBB {'code_1': 'blue'} {'code_2': 'link'}
CodePudding user response:
My original answer did not take into account the order of the list being different.
I am assuming that the keys in the dictionaries are consistent, i.e. code_1, code_2 etc. In order to take into acouunt a different ordering of the list you could do this.
list_ = df["pn"].apply(lambda x: x.strip("[]").split(", "))
df["color"] = [dict_ for mapping in list_ for dict_ in mapping if "code_1" in dict_]
df["code"] = [dict_ for mapping in list_ for dict_ in mapping if "code_2" in dict_]
df.loc[:, ["id", "name", "color", "code"]]
If you create a new dataframe with the items out of order
a = [
{'id': 1, 'name': 'AAA', 'pn':"[{'code_1': 'green'}, {'code_2': 'link'}, {'code_3': '10'}]"},
{'id': 2, 'name': 'BBB', 'pn': "[{'code_2': 'link'}, {'code_1': 'blue'}, {'code_3': '15'}]"},
{'id': 3, 'name': 'CCC', 'pn': "[{'code_3': '15'}, {'code_2': 'link'}, {'code_1': 'red'}]"},
]
df = pd.DataFrame(a)
Which would look like
id name pn
0 1 AAA [{'code_1': 'green'}, {'code_2': 'link'}, {'code_3': '10'}]
1 2 BBB [{'code_2': 'link'}, {'code_1': 'blue'}, {'code_3': '15'}]
2 3 CCC [{'code_3': '15'}, {'code_2': 'link'}, {'code_1': 'red'}]
You would get this output:
id name color code
0 1 AAA {'code_1': 'green'} {'code_2': 'link'}
1 2 BBB {'code_1': 'blue'} {'code_2': 'link'}
2 3 CCC {'code_1': 'red'} {'code_2': 'link'}