I have a dataframe that looks like this:
country,region,region_id,year,doy,variable_a,num_pixels
USA, Iowa,12345,2022,1,32.2,100
USA, Iowa,12345,2022,2,12.2,100
USA, Iowa,12345,2022,3,22.2,100
USA, Iowa,12345,2022,4,112.2,100
USA, Iowa,12345,2022,5,52.2,100
The year in the dataframe above is 2022. I have more dataframes for other years starting from 2010 onwards.
I have also dataframes for other variables: variable_b, variable_c.
I want to combine all these dataframes into a single dataframe such that
The years are listed vertically, one below the other
the data for the different variables is listed horizontally. The output should look like this:
country,region,region_id,year,doy,variable_a,variable_b,variable_c
USA, Iowa,12345,2010,1,32.2,44,101
USA, Iowa,12345,2010,2,12.2,76,2332
... ...
USA, Iowa,12345,2022,1,321.2,444,501
USA, Iowa,12345,2022,2,122.2,756,32
What is the most efficient way to achieve this?
CodePudding user response:
IIUC, this should work for you:
data1 = {
'country': {0: 'USA', 1: 'USA', 2: 'USA', 3: 'USA', 4: 'USA'},
'region': {0: ' Iowa', 1: ' Iowa', 2: ' Iowa', 3: ' Iowa', 4: ' Iowa'},
'region_id': {0: 12345, 1: 12345, 2: 12345, 3: 12345, 4: 12345},
'year': {0: 2022, 1: 2022, 2: 2022, 3: 2022, 4: 2022},
'doy': {0: 1, 1: 2, 2: 3, 3: 4, 4: 5},
'variable_a': {0: 32.2, 1: 12.2, 2: 22.2, 3: 112.2, 4: 52.2},
'num_pixels': {0: 100, 1: 100, 2: 100, 3: 100, 4: 100}
}
data2 = {
'country': {0: 'USB', 1: 'USB', 2: 'USB', 3: 'USB', 4: 'USB'},
'region': {0: ' Iowb', 1: ' Iowb', 2: ' Iowb', 3: ' Iowb', 4: ' Iowb'},
'region_id': {0: 12345, 1: 12345, 2: 12345, 3: 12345, 4: 12345},
'year': {0: 2021, 1: 2021, 2: 2021, 3: 2021, 4: 2021},
'doy': {0: 1, 1: 2, 2: 3, 3: 4, 4: 5},
'variable_b': {0: 32.2, 1: 12.2, 2: 22.2, 3: 112.2, 4: 52.2},
'num_pixels': {0: 100, 1: 100, 2: 100, 3: 100, 4: 100}
}
data3 = {
'country': {0: 'USC', 1: 'USC', 2: 'USC', 3: 'USC', 4: 'USC'},
'region': {0: ' Iowc', 1: ' Iowc', 2: ' Iowc', 3: ' Iowc', 4: ' Iowc'},
'region_id': {0: 12345, 1: 12345, 2: 12345, 3: 12345, 4: 12345},
'year': {0: 2020, 1: 2020, 2: 2020, 3: 2020, 4: 2020},
'doy': {0: 1, 1: 2, 2: 3, 3: 4, 4: 5},
'variable_c1': {0: 32.2, 1: 12.2, 2: 22.2, 3: 112.2, 4: 52.2},
'variable_c2': {0: 32.2, 1: 12.2, 2: 22.2, 3: 112.2, 4: 52.2},
'num_pixels': {0: 100, 1: 100, 2: 100, 3: 100, 4: 100}
}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
df3 = pd.DataFrame(data3)
dfn = [df1, df2, df3]
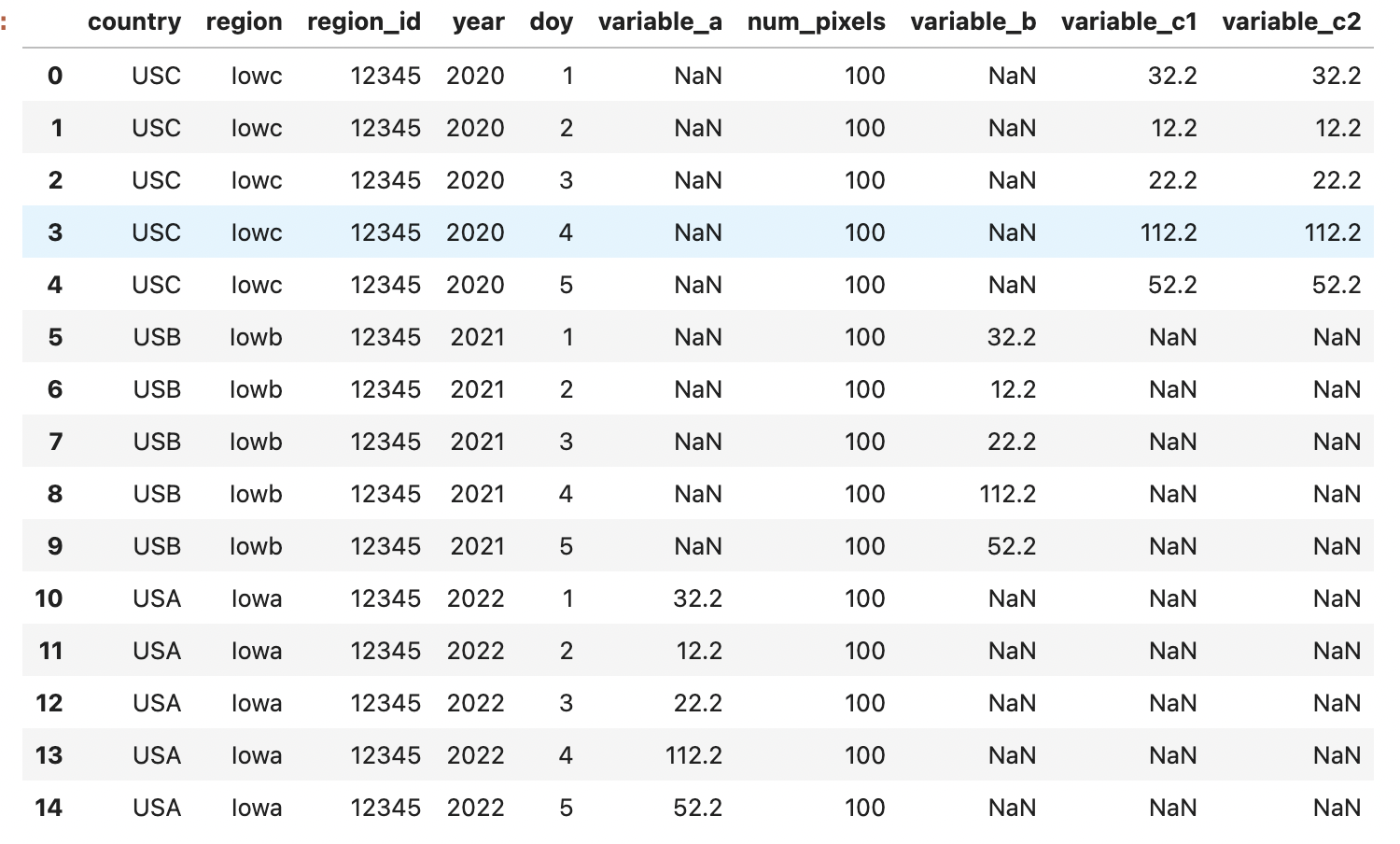
pd.concat(dfn, axis=0).sort_values(['year', 'country', 'region']).reset_index(drop=True)
Output:
CodePudding user response:
Use pd.concat method to do this efficiently. The method does the work by listing all the data frames in vertical order and also creates new columns for all the new variables.
Here is an example of how pd.concat works I created with duplicate data.
CODE
import pandas as pd
df1 = pd.DataFrame({"country": ["USA", "USA", "USA"], "region": ["Iowa", "Iowa", "Iowa"],
"region_id": [12345, 12345, 12345], "year": [2022, 2022, 2022], "doy": [1, 2, 3],
"variable_a": [32.2, 12.2, 22.2], "num_pixles": [100, 100, 100]})
df2 = pd.DataFrame({"country": ["USA", "USA", "USA"], "region": ["Iowa", "Iowa", "Iowa"],
"region_id": [12345, 12345, 12345], "year": [2020, 2020, 2020], "doy": [1, 2, 3],
"variable_b": [54.2, 62.2, 2.2], "num_pixles": [100, 100, 100]})
df_list = [df1, df2] # list of dataframes
res = pd.concat(df_list) # concat the list of dataframes
res = res.sort_values(by="year").reset_index(drop=True) # To make sure that the rows are sorted based on year
print(res)
OUTPUT
country region region_id year doy variable_a num_pixles variable_b
0 USA Iowa 12345 2020 1 NaN 100 54.2
1 USA Iowa 12345 2020 2 NaN 100 62.2
2 USA Iowa 12345 2020 3 NaN 100 2.2
3 USA Iowa 12345 2022 1 32.2 100 NaN
4 USA Iowa 12345 2022 2 12.2 100 NaN
5 USA Iowa 12345 2022 3 22.2 100 NaN