I have the following dataframe:
from numpy import tile
group = np.repeat(['A','B'],10)
number = np.tile(range(0,10),2)
df = pd.DataFrame({
'group': group,
'number' : number,
'value' : np.random.rand(len(number))
})
and I want to create a new column where I perform a series of operations for each group, but I'm running into all sort of problems and my code is looking very clumsy.
The end goal is the following:
- For each group and number 0, df['New'] = 1, or any other constant number K
- For each group and number 1 to 9, df['New'] = df['New' - 1] * ( 1 - df['value' - 1] ), where the value is taken from the row above, which is what I mean by the "- 1" inside the brackets.
- For each group a new row is added, in this case corresponding to number 9 1 = 10, so that the operation above can be included as well.
So far what I've managed is the following:
df = df.set_index(['group', 'number'])
df['Constant'] = 1
df['New'] = df['Constant'] * (1 - df['value'])
def f(x):
x.loc[('', 10), :] = ''
return x
df = df.groupby(level=0, group_keys=False).apply(f)
df['New'] = df.groupby('group').New.shift(1)
But here the shift operation is not working for me, and I still need to preserve the value of the constant in the first position for df['New'] instead of NaN from shifting.
Any pointers and ways to clean up this code are greatly appreaciated.
Edit: A simpler example would be like the following:
CodePudding user response:
For each of the group, you can iterate through the rows in group and set the row value from previous rows.
In the below code, i is the index within each group and group.iloc[i].name gives you the index value corresponding to the original dataframe.
K = 1 # YOUR CONSTANT
df['new'] = K
def func(group):
for i in range(1, len(group)):
df.loc[group.iloc[i].name, 'new'] = df.iloc[group.iloc[i-1].name].new * (1 - group.iloc[i-1].value)
df.groupby('group').apply(func)
which gives us the expected output :
df = pd.DataFrame({
'group': ['A', 'A', 'A', 'A'],
'number' : [0, 1, 2, 3],
'value' : [0.5, 0.4, 0.3, 0]
})
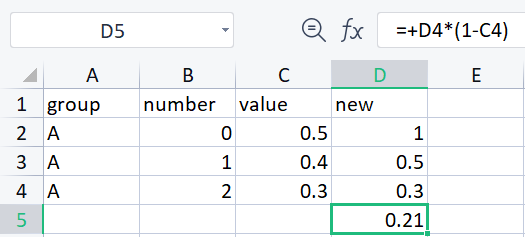
group number value new
0 A 0 0.5 1.00
1 A 1 0.4 0.50
2 A 2 0.3 0.30
3 A 3 0.0 0.21
Also for the below values of group, number and new the dataframe would be
group number value new
0 A 0 0.311951 1.000000
1 A 1 0.022941 0.688049
2 A 2 0.174398 0.672264
3 A 3 0.299853 0.555022
4 A 4 0.725469 0.388597
5 A 5 0.730307 0.106682
6 A 6 0.554905 0.028771
7 A 7 0.815290 0.012806
8 A 8 0.816718 0.002365
9 A 9 0.011935 0.000434
10 B 0 0.153680 1.000000
11 B 1 0.229228 0.846320
12 B 2 0.542225 0.652320
13 B 3 0.219170 0.298616
14 B 4 0.628088 0.233168
15 B 5 0.396675 0.086718
16 B 6 0.646968 0.052319
17 B 7 0.380830 0.018470
18 B 8 0.837341 0.011436
19 B 9 0.531990 0.001860