I'm wondering if there is a way to speed up the calculation of guaranteed promotion in football (soccer) for a given football league table. It seems like there is a lot of structure to the problem so the exhaustive solution is perhaps slower than necessary.
In the problem there is a schedule (a list of pairs of teams) that will play each other in the future and a table (map) of points each team has earned in games in the past. I've included a sample real life points table below. Each future game can be won, lost or tied and teams earn 3 points for a win and 1 for a tie. Points (Pts) is what ultimately matters for promotion and num_of_promoted_teams (positive integer, usually around 1-3) are promoted at the end of each season.
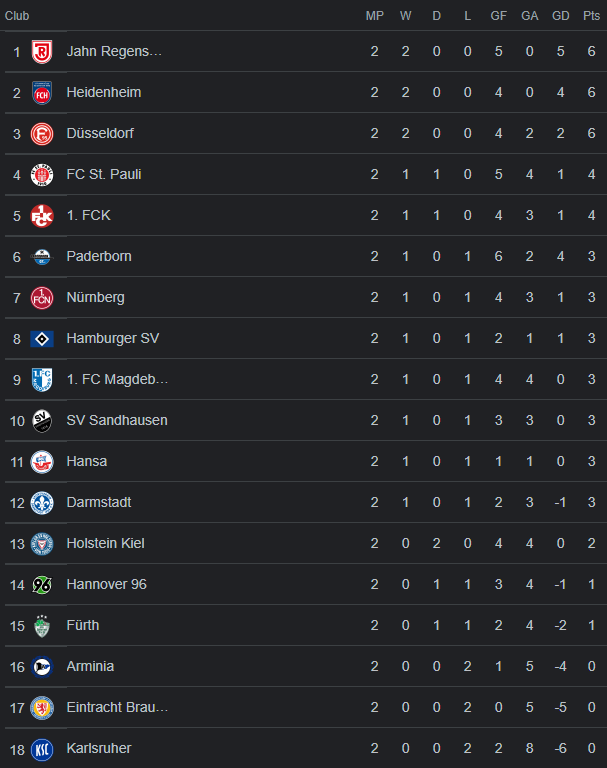
The problem is to determine which (if any) teams are currently guaranteed promotion. Where guaranteed promotion means that no matter the outcome of the final games the team must end up promoted.
def promoted(num_of_promoted_teams, table, schedule):
return guaranteed_promotions
I've been thinking about using depth first search (of the future game results) to eliminate teams which would lower the average but not the worst case performance. This certainly help early in the season, but the problem could become large in mid-season before shrinking again near the end. It seems like there might be a better way.
CodePudding user response:
A constraint solver should be fast enough in practice thanks to clever pruning algorithms, and hard to screw up. Here’s some sample code with the OR-Tools CP-SAT solver.
from ortools.sat.python import cp_model
def promoted(num_promoted_teams, table, schedule):
for candidate in table.keys():
model = cp_model.CpModel()
final_table = table.copy()
for home, away in schedule:
home_win = model.NewBoolVar("")
draw = model.NewBoolVar("")
away_win = model.NewBoolVar("")
model.AddBoolOr([home_win, draw, away_win])
model.AddBoolOr([home_win.Not(), draw.Not()])
model.AddBoolOr([home_win.Not(), away_win.Not()])
model.AddBoolOr([draw.Not(), away_win.Not()])
final_table[home] = 3 * home_win draw
final_table[away] = draw 3 * away_win
candidate_points = final_table[candidate]
num_not_behind = 0
for team, team_points in final_table.items():
if team == candidate:
continue
is_behind = model.NewBoolVar("")
model.Add(team_points < candidate_points).OnlyEnforceIf(is_behind)
model.Add(candidate_points <= team_points).OnlyEnforceIf(is_behind.Not())
num_not_behind = is_behind.Not()
model.Add(num_promoted_teams <= num_not_behind)
solver = cp_model.CpSolver()
status = solver.Solve(model)
if status == cp_model.INFEASIBLE:
yield candidate
print(*promoted(2, {"A": 10, "B": 8, "C": 8}, [("B", "C")]))
CodePudding user response:
Here’s an alternative solution that is less extensible and probably slower in exchange for being self-contained and predictable.
This solution consists of an algorithm to test whether a particular team can finish behind a particular set of other teams (assuming unfavorable tie-breaking), wrapped in a loop over pairs consisting of a top-k team ℓ and a set of k teams W that might or might not finish ahead of ℓ (where k is the number of promoted teams).
If there were no draws, then we could use bipartite matching. Mark ℓ as having lost its remaining matches and mark W as having won their matches against teams not in W. On one side of the bipartite graph, there are nodes corresponding to matches between members of W. On the other side, there are zero or more nodes for each team in W, corresponding to the number of matches that that team must win to pull ahead of ℓ. If there is a matching that completely matches the latter side, then W can finish collectively in front of ℓ, and ℓ is not guaranteed promotion.
This could be extended easily if wins were 2 points instead of 3, but alas, 3 points causes the problem not to be convex, and we’re going to need some branching. The simplest branching method depends on the observation that it’s better for two teams to each win once and lose once against each other than draw twice. Hence, loop over all subsets of at most k choose 2 pairs of teams and run the algorithm above after marking each pair in the subset as having drawn once.
(I could propose improvements, but k is small, computers are cheap, programmers are expensive, and sports fans are relentless.)