I have df with some string values.
so = pd.DataFrame({
"col1": ["row0", "row1", "row2"],
"col2": ["A", "B", "C"],
"col3": ["A", "A", "B"],
"col4": ["B", "A", "B"],
})
I need to create pivot table where:
- index is values from column "col1"
- columns are unique values from columns ['col2':'col4']
- values at the intersection are count of column name matches for every row
For my example, the answer should be:
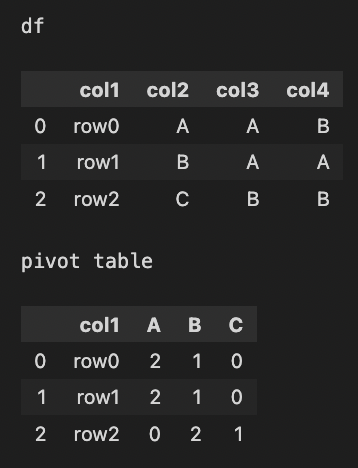
Please help... thank you in advance
CodePudding user response:
melt and crosstab:
df2 = so.melt('col1')
pd.crosstab(df2['col1'], df2['value'])
or melt and groupby.count:
so.melt('col1').groupby(['col1', 'value']).size().unstack(fill_value=0)
output:
value A B C
col1
row0 2 1 0
row1 2 1 0
row2 0 2 1
NB. for the exact output, use .reset_index().rename_axis(columns=None)
CodePudding user response:
here is one way to do it
df.melt('col1').pivot_table(index='col1', columns='value', aggfunc=(lambda x: int(x.size)) ).fillna(0).reset_index()
col1 variable
value A B C
0 row0 2.0 1.0 0.0
1 row1 2.0 1.0 0.0
2 row2 0.0 2.0 1.0