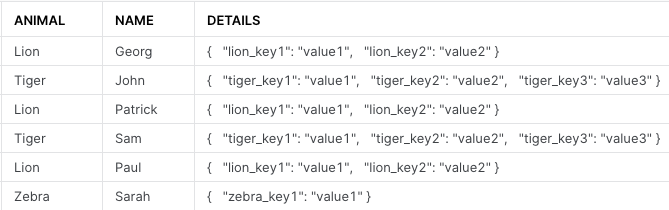
I have one big table in a snowflake db which I want to split into smaller tables according to a column while flattening one column into many columns.
The big table shows animals of three categories (lion, tiger, zebra). I want to split it up into a separate lion, tiger and zebra table. On top I want to flatten a json blob (column "Details") into different columns.
How can I do that?
One way to do it is to write a user defined function with snowpark (Python), convert the table to a pandas DataFrame and then use normal Python code. I think there is a simpler way without the costly transformation to a pandas DataFrame. Maybe there even is a solution in pure SQL.
Original table
| Animal | Name | Details (json blob) |
|---|---|---|
| Lion | Georg | lion key1: value1, lion key2: value2 |
| Tiger | John | tiger key1: value1, tiger key2: value2, tiger key3: value3 |
| Lion | Patrick | lion key1: value1, lion key2: value2 |
| Tiger | Sam | tiger key1: value1, tiger key2: value2, tiger key3: value3 |
| Lion | Paul | lion key1: value1, lion key2: value2 |
| Zebra | Sarah | zebra key1: value1 |
New table: Lion table
| Name | lion key1 | lion key2 |
|---|---|---|
| Georg | value1 | value2 |
| Patrick | value1 | value2 |
| Paul | value1 | value2 |
New table: tiger table
| Name | tiger key1 | tiger key2 | tiger key3 |
|---|---|---|---|
| John | value1 | value2 | value3 |
| Sam | value1 | value2 | value3 |
New table: zebra table
| Name | zebra key1 |
|---|---|
| Sarah | value1 |
CodePudding user response:
First, let's setup your data so we can play with it:
create temp table all_animals as
with data as (
select split(value, '\t') x, x[0]::string animal, x[1]::string name
, parse_json('{' || regexp_replace(x[2], '([a-z] ) key([0-9]): (value[0-9])', '"\\1_key\\2": "\\3"') || '}') details
from table(split_to_table(
$$Lion Georg lion key1: value1, lion key2: value2
Tiger John tiger key1: value1, tiger key2: value2, tiger key3: value3
Lion Patrick lion key1: value1, lion key2: value2
Tiger Sam tiger key1: value1, tiger key2: value2, tiger key3: value3
Lion Paul lion key1: value1, lion key2: value2
Zebra Sarah zebra key1: value1$$
, '\n'))
)
select *
from data
Now let's create the tables where we will insert the data:
create temp table lions (name string, v1 string, v2 string);
create temp table tigers (name string, v1 string, v2 string, v3 string);
And now comes the answer to the question: Snowflake SQL supports conditional inserts, so we can insert each row into a different table with a different schema:
insert first
when animal='Lion'
then into lions (name, v1, v2) values (name, details:lion_key1, details:lion_key2)
when animal='Tiger'
then into tigers (name, v1, v2, v3) values (name, details:tiger_key1, details:tiger_key2, details:tiger_key3)
select *
from all_animals
;
As seen above, use INSERT WHEN to look at each row and decide into which table you'll insert them into, each with possibly a different schema.
For this solution you need to know the schema of each resulting table. If you don't know that, then we can explore in a different question how to create tables after exploring the keys to be flattened out of objects.