My df look like this:
close in_uptrend count_uptrend
83 2 True 1
84 3 True 2
85 4 True 3
86 1 True 4
87 3 True 5
88 5 True 6
89 7 True 7
90 6.6 True 8
91 8 True 9
92 8.9 True 10
93 9 True 11
94 11 True 12
95 10 False 1
96 9 False 2
97 8 False 3
98 5 False 4
I want to create a new column named 'percent_trend' that calculate the increase of the 'close' column value, when a switch happens between 'in_trend' = 'True' to 'False' and percent decrease when a switch happens between 'in_trend' = 'False' to 'True'
Note that the column 'count_uptrend' is equal 1 when there is a switch between True and False.
Note sure if I explain it clearly, but the excepted result should help:
Expected result:
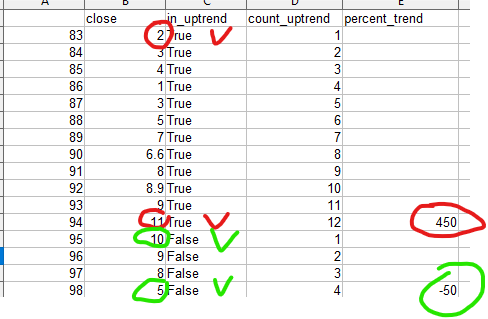
close in_uptrend count_uptrend percent_trend
83 2 True 1
84 3 True 2
85 4 True 3
86 1 True 4
87 3 True 5
88 5 True 6
89 7 True 7
90 6.6 True 8
91 8 True 9
92 8.9 True 10
93 9 True 11
94 11 True 12 450
95 10 False 1
96 9 False 2
97 8 False 3
98 5 False 4 -50
CodePudding user response:
Annotated code
# identify blocks of continuous True/False values
b = df['in_uptrend'].diff().ne(0).cumsum()
# group the 'close' column by blocks
g = df['close'].groupby(b)
# Broadcast the first and last value per group
last, first = g.transform('last'), g.transform('first')
# calculate percent change
df['pct_trend'] = (last - first) / first * 100
# Mask the duplicate values
df['pct_trend'] = df['pct_trend'].mask(b.duplicated(keep='last'))
close in_uptrend count_uptrend pct_trend
83 2.0 True 1 NaN
84 3.0 True 2 NaN
85 4.0 True 3 NaN
86 1.0 True 4 NaN
87 3.0 True 5 NaN
88 5.0 True 6 NaN
89 7.0 True 7 NaN
90 6.6 True 8 NaN
91 8.0 True 9 NaN
92 8.9 True 10 NaN
93 9.0 True 11 NaN
94 11.0 True 12 450.0
95 10.0 False 1 NaN
96 9.0 False 2 NaN
97 8.0 False 3 NaN
98 5.0 False 4 -50.0