Say I have a dataframe
df = pd.DataFrame({
'column_1': ['ABC DEF', 'JKL', 'GHI ABC', 'ABC ABC', 'DEF GHI', 'DEF', 'DEF DEF', 'ABC GHI DEF ABC'],
'column_2': [9, 2, 3, 4, 6, 2, 7, 1 ]
})
df
column_1 column_2
0 ABC DEF 9
1 GHI ABC 3
2 ABC ABC 4
3 DEF GHI 6
4 DEF 2
5 DEF DEF 7
6 ABC GHI DEF ABC 1
I want to count the number of times each of my regex pattern group is present in the column.
For simplicity, say the pattern is the word ABC and DEF then I need the count of those in all the rows.
Expected output :
column_1 column_2 Group1_count Group2_count
0 ABC DEF 9 1 1
1 JKL 9 0 0
2 GHI ABC 3 1 0
3 ABC ABC 4 2 0
4 DEF GHI 6 0 1
5 DEF 2 0 1
6 DEF DEF 7 0 2
7 ABC GHI DEF ABC 1 2 1
This is what I tried, where I am unable to figure out how to move ahead to get the count value.
df['column_1'].str.extractall('(ABC)|(DEF)').groupby(level=0).first()
0 1
0 ABC DEF
2 ABC None
3 ABC None
4 None DEF
5 None DEF
6 None DEF
7 ABC DEF
A vector solution/one liner approach would be appreciated for this question.
Also note that in this example I have ABC and DEF for simplicity but it could be a complex regex pattern as well.
CodePudding user response:
df = pd.DataFrame({'column_1': ['ABC DEF', 'GHI ABC', 'ABC ABC', 'DEF GHI', 'XYZ', 'DEF DEF', 'ABC GHI DEF ABC'],
'column_2': [9, 3, 4, 6, 2, 7, 1]})
df = df.merge(df['column_1'].str.extractall('(ABC)|(DEF)').groupby(level=0).count(), how='outer', left_index=True,
right_index=True).fillna(0).rename(columns={0: "Group1_count", 1: "Group2_count"}).astype(
{"Group1_count": 'int32', "Group2_count": 'int32'})
print(df)
Output:
column_1 column_2 Group1_count Group2_count
0 ABC DEF 9 1 1
1 GHI ABC 3 1 0
2 ABC ABC 4 2 0
3 DEF GHI 6 0 1
4 XYZ 2 0 0
5 DEF DEF 7 0 2
6 ABC GHI DEF ABC 1 2 1
CodePudding user response:
Check Below, continuation of your code. You can use 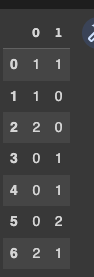
Updated:
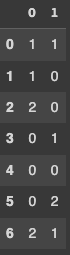
df['column_1'].str.extractall('(ABC)|(DEF)|''').groupby(level=0).agg('count')
CodePudding user response:
You can get the desired result with your approach if you sum the notna instead of first, and then join back with the original df
df.join(df['column_1'].str.extractall('(ABC)|(DEF)').notna().groupby(level=0).sum(), how='left').fillna(0)
Output
column_1 column_2 0 1
0 ABC DEF 9 1.0 1.0
1 JKL 2 0.0 0.0
2 GHI ABC 3 1.0 0.0
3 ABC ABC 4 2.0 0.0
4 DEF GHI 6 0.0 1.0
5 DEF 2 0.0 1.0
6 DEF DEF 7 0.0 2.0
7 ABC GHI DEF ABC 1 2.0 1.0