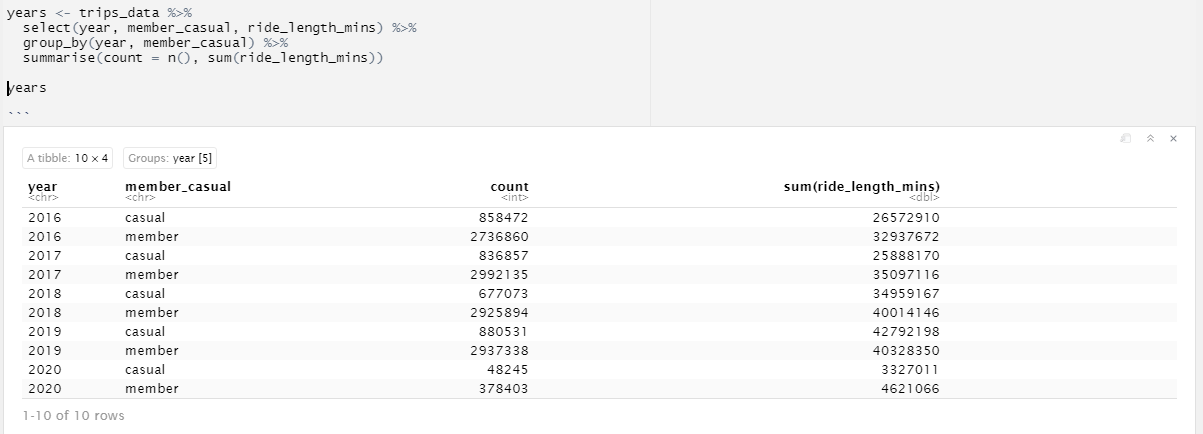
this is the DataFrame I am working on.
I want the data to show the result in percentages corresponding to that year only
I tried grouping them as
years <- trips_data %>%
select(year, member_casual, ride_length_mins) %>%
group_by(year, member_casual) %>%
summarise(count_percentage = n()/nrow(trips_data ), sum(ride_length_mins)) %>%
mutate(percentage_of_rides = scales::percent(percentage_of_rides))
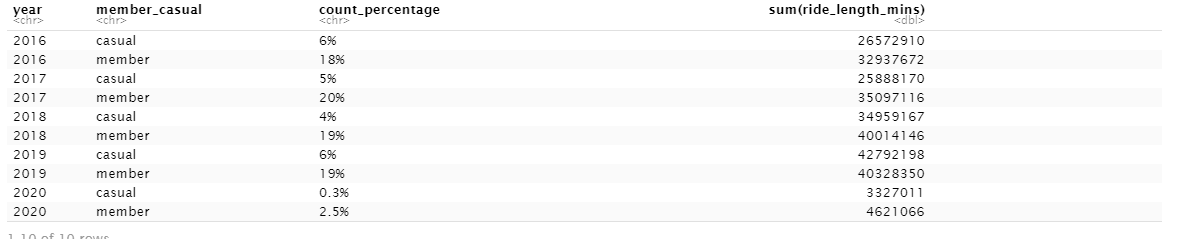
but the result shows each year % as as a part of all 4 years like this
the desired output is like
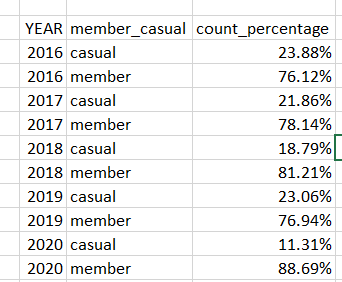
I cannot think of a way to achieve this without making individual variables for each year by filtering. and hard coding
any advice or help is much appreciated, thank you
Here is the Reproducible sample
structure(list(year = c("2016", "2016", "2016", "2016", "2016",
"2016", "2016", "2016", "2016", "2016", "2016", "2016", "2016",
"2016", "2016", "2016", "2016", "2016", "2017", "2017", "2017",
"2017", "2017", "2017", "2017", "2017", "2017", "2017", "2017",
"2017", "2017", "2017", "2017", "2017", "2018", "2018", "2018",
"2018", "2018", "2018", "2018", "2018", "2018"), member_casual = c("casual",
"casual", "casual", "casual", "casual", "casual", "member", "member",
"member", "member", "member", "member", "member", "member", "member",
"member", "member", "member", "casual", "casual", "casual", "casual",
"casual", "casual", "casual", "casual", "casual", "casual", "casual",
"member", "member", "member", "member", "member", "casual", "casual",
"casual", "casual", "casual", "member", "member", "member", "member"
), ride_length_mins = c(28, 21, 2, 27, 27, 22, 14, 11, 4, 18,
4, 10, 16, 11, 13, 8, 10, 21, 15, 22, 23, 15, 16, 16, 16, 25,
16, 12, 23, 14, 4, 6, 5, 7, 24.6833333333333, 7736.13333333333,
22.6833333333333, 24.6833333333333, 7736.13333333333, 22.6833333333333,
52.2166666666667, 52.6333333333333, 49.3)), row.names = c(NA,
-43L), class = "data.frame")
CodePudding user response:
Instead of the nrow(trip_data), we may need to get the row grouped by 'member_casual
library(dplyr)
trips_data %>%
add_count(year, member_casual) %>%
add_count(year, name = 'year_n') %>%
group_by(year, member_casual) %>%
summarise(count_percentage = first(n)/first(year_n),
Sum = sum(ride_length_mins), .groups = "drop") %>%
mutate(count_percentage = scales::percent(count_percentage))
-output
# A tibble: 5 × 4
year member_casual count_percentage Sum
<chr> <chr> <chr> <dbl>
1 2016 casual 33.3% 127
2 2016 member 66.7% 140
3 2017 casual 68.8% 199
4 2017 member 31.2% 36
5 2018 casual 100.0% 15721.
If we want the Sum to be based on percentage
trips_data %>%
add_count(year, member_casual) %>%
add_count(year, name = 'year_n') %>%
group_by(year) %>%
mutate(Sum = sum(ride_length_mins)) %>%
group_by( member_casual, Sum, .add = TRUE) %>%
summarise(count_percentage = first(n)/first(year_n),
.groups = 'drop') %>%
mutate(Sum = Sum * count_percentage,
count_percentage = scales::percent(count_percentage))%>%
group_by(year) %>%
mutate(Sum = Sum/sum(Sum)) %>%
ungroup
# A tibble: 5 × 4
year member_casual Sum count_percentage
<chr> <chr> <dbl> <chr>
1 2016 casual 0.333 33.3%
2 2016 member 0.667 66.7%
3 2017 casual 0.688 68.8%
4 2017 member 0.312 31.2%
5 2018 casual 1 100.0%