Problem
I have a dataframe with duplicates for most of the columns, except the last column. I want to exclude duplicates with null values, and keep duplicates with valid values. I then want to take the duplicate values out and create a separate dataframe with it. At the moment, my approach is laborious (especially as I have a large dataframe).
Reprex
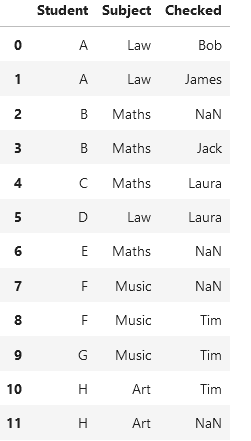
Starting Dataframe
import pandas as pd
import numpy as np
data_input = {'Student': ['A', 'A', 'B', 'B', 'C', 'D', 'E', 'F', 'F', 'G', "H", "H"],
"Subject": ["Law", "Law", "Maths", "Maths", "Maths", "Law", "Maths", "Music", "Music", "Music", "Art", "Art"],
"Checked": ["Bob", "James", np.nan, "Jack", "Laura", "Laura", np.nan, np.nan, "Tim", "Tim", "Tim", np.nan]}
# Create DataFrame
df1 = pd.DataFrame(data_input)
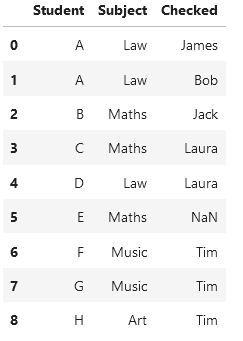
Desired Output
First Attempt
attempt1 = df1.sort_values(['Student', 'Checked'], ascending=False).drop_duplicates(["Student", "Subject"]).sort_index()
I took this from another Q&A on Stack, but it does not give me the outcome I want and I don't understand it.
Attempt 2
#Create Duplicate column
df1["Duplicates"] = df1.duplicated(subset=["Student", "Subject"], keep=False)
#Create list of rows with no duplicates
df_new1 = df1[df1["Duplicates"]==False]
#Create list of rows with duplicates & remove all those with null values
df_new2 = df1[df1["Duplicates"]==True]
df_new3 = df_new2[~df_new2["Checked"].isnull()]
#Combine unique rows, and duplicates without null values
#Keep duplicates without null values
df_new = df_new1.append(df_new3)
#Tidy up
df_new = df_new[["Student", "Subject", "Checked"]].sort_values(by="Student")
df_new
I can then create a list of the duplicates that both appear valid
#Create separate list of duplicates with valid "Checked" values
df_new["Duplicates"] = df_new.duplicated(subset="Student", keep=False)
conflicting_duplicates = df_new[df_new["Duplicates"]==True]
conflicting_duplicates
Help
Is there a better way of doing this?
CodePudding user response:
You could create a new helper column using np.where which will flag the rows that satisfy the conditions you specified. If I understand you correctly you want to keep the rows that are duplicated in 'Student' and 'Subject', and also have a null value in 'Checked' column.
You can then use drop to remove the flagged ones:
import numpy as np
df1['to_drop'] = np.where(
(df1['Student'].isin(df1[df1[['Student','Subject']].duplicated()]['Student'].tolist())
) & (df1['Checked'].isnull()),1,0)
df1.loc[df1.to_drop==0].drop('to_drop',axis=1)
prints:
Student Subject Checked
0 A Law Bob
1 A Law James
3 B Maths Jack
4 C Maths Laura
5 D Law Laura
6 E Maths NaN
8 F Music Tim
9 G Music Tim
10 H Art Tim
CodePudding user response:
You can use groupby and drop NaN values
df.groupby("Student", sort=False).apply(lambda x : x if len(x) == 1 else x.dropna(subset=['Checked'])).reset_index(drop=True)
Output :
This gives us the expected output
Student Subject Checked
0 A Law Bob
1 A Law James
2 B Maths Jack
3 C Maths Laura
4 D Law Laura
5 E Maths NaN
6 F Music Tim
7 G Music Tim
8 H Art Tim
CodePudding user response:
My take using Boolean indexing:
s_idx = ~(df1[(df1.duplicated(subset=['Student','Subject'],keep=False))])['Checked'].isna()
idx = [x for x in df1.index.values if x not in s_idx[~s_idx].index]
df1.iloc[idx]
Output:
Student Subject Checked
0 A Law Bob
1 A Law James
3 B Maths Jack
4 C Maths Laura
5 D Law Laura
6 E Maths NaN
8 F Music Tim
9 G Music Tim
10 H Art Tim
CodePudding user response:
Use boolean indexing:
# is the group containing more than one row?
m1 = df1.duplicated(['Student', 'Subject'], keep=False)
# is the row a NaN in "Checked"?
m2 = df1['Checked'].isna()
# both conditions True
m = m1&m2
# keep if either condition is False
df1[~m]
# to get dropped duplicates
# keep if both are True
df1[m]
Output:
Student Subject Checked
0 A Law Bob
1 A Law James
3 B Maths Jack
4 C Maths Laura
5 D Law Laura
6 E Maths NaN
8 F Music Tim
9 G Music Tim
10 H Art Tim