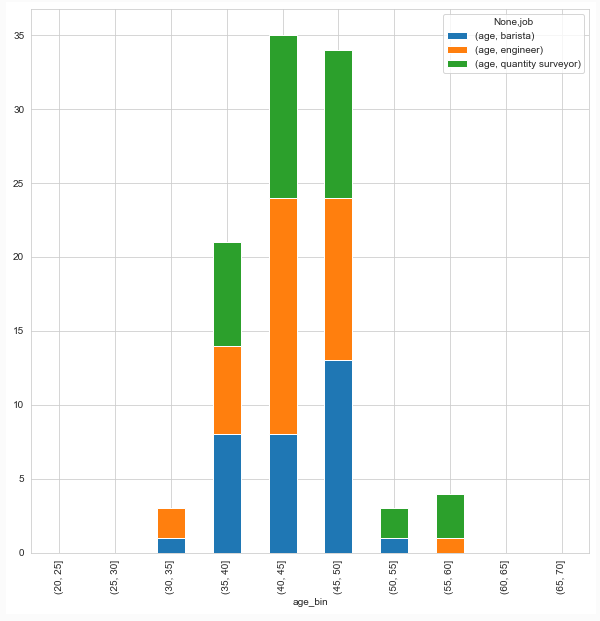
I have data with a numeric and categorical variable. I want to show a histogram of the numeric column, where each bar is stacked by the categorical variable. I tried to do this with ax.hist(data, histtype='bar', stacked=True), but couldn't quite get it to work.
If my data is
df = pd.DataFrame({'age': np.random.normal(45, 5, 100), 'job': np.random.choice(['engineer', 'barista',
'quantity surveyor'], size=100)})
I've organised it like this:
df['binned_age'] = pd.qcut(df.age, 5)
df.groupby('binned_age')['job'].value_counts().plot(kind='bar')
Which gives me a bar chart divided the way I want, but side by side, not stacked, and without different colours for each category.
Is there a way to stack this plot? Or just do it a regular histogram, but stacked by category?
CodePudding user response:
IIUC, you will need to reshape your dataset first - i will do that using pivot_table and use len for an aggregator as that will give you the frequency.
Then you can use a similar code to the one you provided above.
df.drop('age',axis=1,inplace=True)
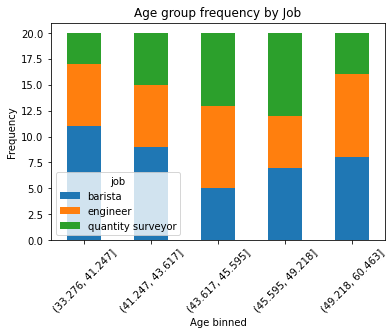
df_reshaped = df.pivot_table(index=['binned_age'], columns=['job'], aggfunc=len)
df_reshaped.plot(kind='bar', stacked=True, ylabel='Frequency', xlabel='Age binned',
title='Age group frequency by Job', rot=45)
prints:
You can use the