I'd like to bucket my dataframe by second and take the mean, whereby if there exist nan values in any bucket, I'd like to return nan.
Example:
import datetime as dt
import pandas as pd
idx = dt.datetime(2009,9,9,13,59,1,1), dt.datetime(2009,9,9,13,59,1,2), dt.datetime(2009,9,9,13,59,2,0)
df = pd.DataFrame(index=[idx], data=[1,None,3])
>>> df
0
2009-09-09 13:59:01.000001 1.0000
2009-09-09 13:59:01.000002 nan
2009-09-09 13:59:02.000000 3.0000
And then
>>> df.resample("1S", label='right', closed='left').mean()
0
2009-09-09 13:59:02 1.0000
2009-09-09 13:59:03 3.0000
>>>
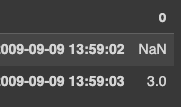
However, what I want is
0
2009-09-09 13:59:02 nan
2009-09-09 13:59:03 3.0000
>>>
I would assume ...mean(skipna=False) would give me the desired result, however, it returns an error:
pandas.errors.UnsupportedFunctionCall: numpy operations are not valid with resample. Use .resample(...).mean() instead
What's the solution here? .mean() on pandas typically accepts the skipna argument.
CodePudding user response:
Check Below code:
def custom_mean(val):
return val.mean(skipna=False)
df.resample("1S", label='right', closed='left').agg({0:custom_mean})
Output:
CodePudding user response:
What you need is:
df.resample("1S").agg(pd.Series.mean, skipna=False)