I have had this data frame before with missing data in numbers and level3, which are both different in dtypes (int str). And i am looking to fill the data based on the Org column. The data in numbers and level3 are always the same for each Org ID.
numbers = [np.nan, 5, 5, 5, np.nan,55,np.nan,55,55,np.nan,555,np.nan,555,555,np.nan]
Org = [1, 1, 1, 1, 1,2, 2, 2, 2, 2,3, 3, 3, 3, 3]
level3 = ["test", np.nan, "test", "test", np.nan, "failed", np.nan, "failed", "failed", "failed",np.nan,'try harder','try harder',np.nan,np.nan]
d = {'col1': numbers, 'col2': Org,'col3':level3}
inital = pd.DataFrame(data = d)
My desired output is the below:
numbers = [5, 5, 5, 5, 5,55,55,55,55,55,555,555,555,555,555]
Org = [1, 1, 1, 1, 1,2, 2, 2, 2, 2,3, 3, 3, 3, 3]
level3 = ["test", "test", "test", "test", "test", "failed", "failed", "failed", "failed", "failed",'try harder','try harder','try harder','try harder','try harder']
d = {'col1': numbers, 'col2': Org,'col3':level3}
final = pd.DataFrame(data = d)
I started by creating an extremely long loop to see if the org was the same, then applying the -1 or -2 or -3 or 1 or 2 or 3 value if it wasn't empty. Still, it seemed ridiculously inefficient and didn't work perfectly, so I thought id come here to see if anyone had any tricks they could teach me.
Thank you
CodePudding user response:
Try Below code - You can drop not required columns :
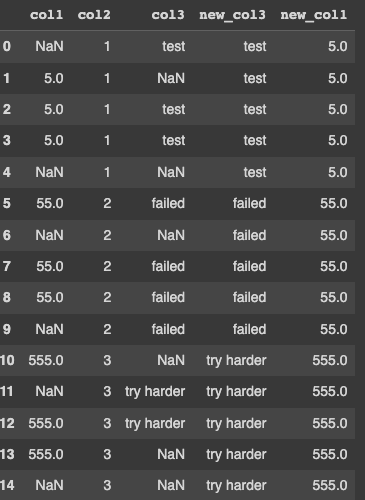
inital.assign(new_col3 = inital.groupby(['col2'])['col3'].transform('first'),
new_col1 = inital.groupby(['col2'])['col1'].transform('max')
)
Output:
CodePudding user response:
Let's try
inital[['col1', 'col3']] = inital.groupby('col2').apply(lambda g: g[['col1', 'col3']].ffill().bfill())
print(inital)
col1 col2 col3
0 5.0 1 test
1 5.0 1 test
2 5.0 1 test
3 5.0 1 test
4 5.0 1 test
5 55.0 2 failed
6 55.0 2 failed
7 55.0 2 failed
8 55.0 2 failed
9 55.0 2 failed
10 555.0 3 try harder
11 555.0 3 try harder
12 555.0 3 try harder
13 555.0 3 try harder
14 555.0 3 try harder