I have some log data tracking invoice processing, like the example below:
Invoice Activity Date
--------------------------------------
A Creation 12-Mar
A Quantity change 13-Mar
A Quantity change 14-Mar
A Payment 17-Mar
B Creation 20-Apr
B Payment 24-Apr
B Payment 29-Apr
I need to show, for every invoice, when the first and last of each activity occurred. For example, for invoice A there were two quantity changes, and I am interested in that date. I need to display everything in an aggregated table with 1 row per invoice as shown below:
Invoice Creation date First quantity change Last payment
---------------------------------------------------------------------
A 12-Mar 13-Mar 17-Mar
B 20-Apr NULL 29-Apr
I have explored a couple of different options but nothing works so far. The most obvious one is to join the table on itself, using the invoice id as the join key. However, this is not possible because of performance issues, as the tables are very large and this would require too many joins.
Another option is to use the first_value and last_value functions, but I am not able to set them up in a way that gives me the results I need, because I can't find a way to somehow put a filter in it.
I have tried this, which doesn't work, but kind of shows what I'm trying to do:
SELECT
Invoice
, first_value(CASE WHEN Activity = 'Quantity Change' THEN Activity ELSE NULL END)
OVER (PARTITION BY Invoice ORDER BY Date)
FROM
Data
Does anyone have any suggestion on how to do this? I am running these transformations in google big query.
Many thanks,
Alessandro
CodePudding user response:
Using PIVOT query,
SELECT * FROM (
SELECT Invoice, Activity,
FORMAT_DATE('%d-%b', MIN(date0) OVER (PARTITION BY Invoice, Activity)) first,
FORMAT_DATE('%d-%b', MAX(date0) OVER (PARTITION BY Invoice, Activity)) last,
FROM sample_table, UNNEST([PARSE_DATE('%d-%b', Date)]) date0
) PIVOT (ANY_VALUE(first) first, ANY_VALUE(last) last FOR REPLACE(Activity, ' ','_') IN ('Creation', 'Payment', 'Quantity_change'));
You can get following results:

And you can make above query more general using a dynamic sql, but I don't think you want to have a table with 100,000 columns.
So, I think below query and a table schema is more practical than a pivoted table.
SELECT DISTINCT Invoice, Activity,
FORMAT_DATE('%d-%b', MIN(date0) OVER (PARTITION BY Invoice, Activity)) first,
FORMAT_DATE('%d-%b', MAX(date0) OVER (PARTITION BY Invoice, Activity)) last,
FROM sample_table, UNNEST([PARSE_DATE('%d-%b', Date)]) date0;
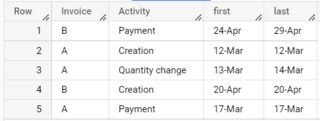
A sameple table used in above queries:
create temp table sample_table as
select 'A' Invoice, 'Creation' Activity, '12-Mar' Date union all
select 'A', 'Quantity change', '13-Mar' union all
select 'A', 'Quantity change', '14-Mar' union all
select 'A', 'Payment', '17-Mar' union all
select 'B', 'Creation', '20-Apr' union all
select 'B', 'Payment', '24-Apr' union all
select 'B', 'Payment', '29-Apr';
CodePudding user response:
You can achieve this by using the MIN and MAX aggregate functions.
WITH inv AS
(
SELECT "A" AS Invoice, 'Creation' as Activity, DATE '2022-03-12' as Date UNION ALL
SELECT "A" AS Invoice, 'Quantity change' as Activity, DATE '2022-03-13' as Date UNION ALL
SELECT "A" AS Invoice, 'Quantity change' as Activity, DATE '2022-03-14' as Date UNION ALL
SELECT "A" AS Invoice, 'Payment' as Activity, DATE '2022-03-17' as Date UNION ALL
SELECT "B" AS Invoice, 'Creation' as Activity, DATE '2022-04-20' as Date UNION ALL
SELECT "B" AS Invoice, 'Payment' as Activity, DATE '2022-04-24' as Date UNION ALL
SELECT "B" AS Invoice, 'Payment' as Activity, DATE '2022-04-29' as Date
)
SELECT
Invoice,
MIN(IF(inv.Activity = 'Creation', Date, NULL)) as CreationDate,
MIN(IF(inv.Activity = 'Quantity change', Date, NULL)) as FirtsQuantityChange,
MAX(IF(inv.Activity = 'Payment', Date, NULL)) as LastPayment
FROM inv
GROUP BY Invoice