I have a table, which shows information regarding trades. d_diff column shows the difference between endtime and begtime, measured in a number of days.
I want those rows, where d_diff > 1, to make duplicated (d_diff shows the number of duplicated rows.

The final dataset should look like in a table below. As you can see, in this table the difference between endtime and begtime is 1 (the table is more granular).
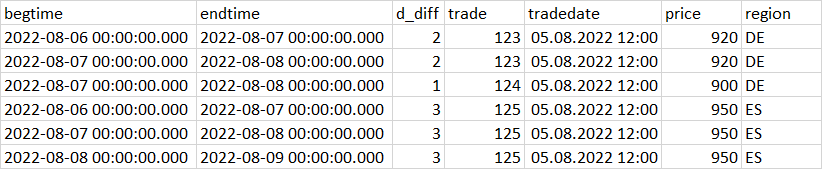
How can it be done? I tried to do kind of this
select * from main a
full outer join
main b
on a.begtime <= b.endtime
CodePudding user response:
You can use a recursive CTE to generate series of repeatable rows like this
WITH cte(begtime, endtime, d_diff, trade, tradedate, price, region, d_diff_decr) AS (
SELECT
*,
d_diff AS d_diff_decr
FROM t
UNION ALL
SELECT
begtime,
endtime,
d_diff,
trade,
tradedate,
price,
region,
d_diff_decr - 1 AS d_diff_decr
FROM cte
WHERE d_diff_decr > 1
)
SELECT
begtime,
endtime,
d_diff,
trade,
tradedate,
price,
region
FROM cte
ORDER BY trade
CodePudding user response:
You can inner join with a tally table / numbers list.
Example:
with tally as (
select v from (values(1),(2),(3))v(v)
)
select m.*
from main m
join tally t on t.v <= m.d_diff;