I'm trying to scrap a 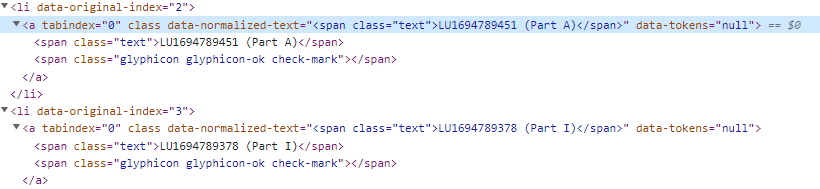
So far, i have tried the following, but it doesn't seem to work.
driver.find_element(By.XPATH, '//a[@data-normalized-text="<span >LU1694789451 (Part A)</span>"]')
I am getting the following error:
InvalidSelectorException: invalid selector: Unable to locate an element with the xpath expression //a[@data-normalized-text="<span >LU1694789451 (Part A)</span>"] because of the following error:
SyntaxError: Failed to execute 'evaluate' on 'Document': The string '//a[@data-normalized-text="<span >LU1694789451 (Part A)</span>"]' is not a valid XPath expression.
(Session info: chrome=103.0.5060.114)
Can someone please help me with this?
CodePudding user response:
The following code will return all a tags containing a span with class text, as from what I could see in page, all links with that particular data-normalized-text attribute have. The setup is for linux, however you can adapt the code to your own, just observe the imports and the code after defining the browser/driver:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
chrome_options = Options()
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument('disable-notifications')
webdriver_service = Service("chromedriver/chromedriver") ## path to where you saved chromedriver binary
browser = webdriver.Chrome(service=webdriver_service, options=chrome_options)
url = 'https://www.dnca-investments.com/documents'
browser.get(url)
elems = WebDriverWait(browser,10).until(EC.presence_of_all_elements_located((By.XPATH, "//span[@class='text']/parent::a")))
print('Total links:', len(elems))
for elem in elems:
print(len(elems))
print(elem.get_attribute('outerHTML'))
This will return:
Total links: 1205
<a tabindex="0" data-normalized-text="<span class="text">LU1791428052 (Part H-I (CHF))</span>" data-tokens="null"><span >LU1791428052 (Part H-I (CHF))</span><span ></span></a>
<a tabindex="0" data-normalized-text="<span class="text">LU1694789535 (Part B)</span>" data-tokens="null"><span >LU1694789535 (Part B)</span><span ></span></a>
<a tabindex="0" data-normalized-text="<span class="text">LU1694789451 (Part A)</span>" data-tokens="null"><span >LU1694789451 (Part A)</span><span ></span></a>
<a tabindex="0" data-normalized-text="<span class="text">LU1694789378 (Part I)</span>" data-tokens="null"><span >LU1694789378 (Part I)</span><span ></span></a>
[...]
Note you can drill down to further ancestors, and then return and grab the links you want, depending on the category etc. Selenium documentation can be found at https://www.selenium.dev/documentation/
CodePudding user response:
<a> tags are generally clickable.
To identify the the clickable element you need to induce WebDriverWait for the element_to_be_clickable() and you can use either of the following locator strategies:
Using CSS_SELECTOR:
element = WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.CSS_SELECTOR, "a[data-normalized-text*='LU1694789451'] span")))Using XPATH:
element = WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.XPATH, "//a[contains(@data-normalized-text, 'LU1694789451')]//span[contains(., 'LU1694789451')]")))Note : You have to add the following imports :
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC