I would like to extract the text inside the range "text: ....." from this dataframe and create another column with that value.
This is my Pandas Dataframe
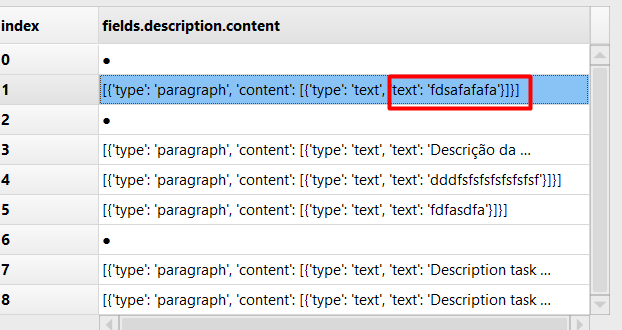
issues_df['new_column'] = issues_df['fields.description.content'].apply(lambda x: x['text'])
However, it returns the following error:
issues_df['new_column'] = issues_df['fields.description.content'].apply(lambda x: x['text'])
TypeError: Object 'float' is not writable.
Any suggestions?
Thanks in advance.
CodePudding user response:
Problem is NaN in column, you can try .str accessor
issues_df['new_column'] = issues_df['fields.description.content'].str[0].str['content'].str[0].str['text']
CodePudding user response:
That could be a good task for the rather efficient json_normalize:
df['new_column'] = pd.json_normalize(
df['fields.description.content'], 'content'
)['text']