I have two dataframes, the first is this one, created with the following code:
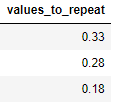
values_to_repeat = [0.33, 0.28, 0.18]
df1 = pd.DataFrame({'values_to_repeat':values_to_repeat})
The second one is the following:
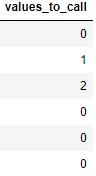
values_to_call = [0,1,2,0,0,0]
df2 = pd.DataFrame({'values_to_call':values_to_call})
What I need to do is to add a column to the second data frame that contains lists of values taken from the first data frame. I will show it and then explain it with words:
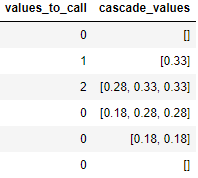
The lists should contain the first value of the column "values_to_repeat" repeated for the value of "values_to_call", and then in the following 2 rows, it should take the second and the third value, until disappearing in row = (i 3).
Explaining it row by row:
1) there is an empty list because there is a 0 in "value_to_call"
2) there is [0.33] because there is a 1 in "values_to_call"
3) there is the list [0.28, 0.33, 0.33] where the first value is the value of row number 2 that decreased to 0.28 and then 2 new 0.33 because there is a 2 in "values_to_call"
4) there is the list [0.18, 0.28, 0.28] where the first value is the value of row number 2 that decreased to 0.18 and the other 2 values are the values generated in row number 3 that decreased to 0.28
5) there is the list [0.18, 0.18], now the value generated in row number 2, after decreasing 2 times it disappeard, while the 2 values generated in row number 3 decrease to 0.18
6) there is an empty list because after appearing in i, i 1 and i 2, at i 3 the values generated in row number 3 disappeared as well
CodePudding user response:
Hi you can try this i know it is not the best answer
previous_list=[]
cascade_values=[]
dict_to_replace={0.28:0.18,0.33:0.28}
for _, value in df2.iterrows():
while 0.18 in previous_list: previous_list.remove(0.18)
previous_list=list(map(lambda x:dict_to_replace[x],previous_list))
if value["values_to_call"]==1:
previous_list=previous_list [0.33]
elif value["values_to_call"]==2:
previous_list=previous_list [0.33,0.33]
cascade_values.append(previous_list)
df2["cascade_values"]=pd.Series(cascade_values)
CodePudding user response:
This was a nice brainbreaker. I put the cascading in a separate function but you could put it in the main loop at the bottom. I'm not sure if this is anywhere near optimal, but it does what it needs to do.
import pandas as pd
values_to_repeat = [0.33, 0.28, 0.18]
df_repeat = pd.DataFrame({"values_to_repeat": values_to_repeat})
values_to_call = [0, 1, 2, 0, 0, 0]
df_call = pd.DataFrame({"values_to_call": values_to_call})
# new column with empty lists
df_call["cascade_values"] = [[] for _ in range(df_call.shape[0])]
def cascade_values(values):
result = []
# set max value based on df_repeat row count, and decrease by one
idxmax = df_repeat.shape[0] -1
for v in values:
# the below only works when there are no duplicates in values_to_repeat
idx = df_repeat.values_to_repeat[df_repeat.values_to_repeat == v].index.tolist()[0]
if idx < idxmax:
# only add values if the current value is not the last row of the column
result.append(df_repeat.iloc[idx 1]["values_to_repeat"])
return result
# set this outside the loop once, so the iloc doesn't get done each loop
value_to_add = df_repeat.iloc[0]["values_to_repeat"]
previous_values = []
for i in range(df_call.shape[0] -1):
current_values = cascade_values(previous_values)
for _ in range(df_call.iloc[i]["values_to_call"]):
current_values.append(value_to_add)
df_call.at[i, "cascade_values"] = current_values
previous_values = current_values
print(df_call)
output
values_to_call cascade_values
0 0 []
1 1 [0.33]
2 2 [0.28, 0.33, 0.33]
3 0 [0.18, 0.28, 0.28]
4 0 [0.18, 0.18]
5 0 []