I've got a big dataframe which shows the amount of each product and their costs for different products. However, I want to transform (unpivot) the dataframe into a long dataframe with each product name as an ID and their amounts and costs in two different columns. I've tried the pd.melt and ireshape functions, but neither seems to work.
Here is an example of what I am trying to do. Here is my table
df = pd.DataFrame({ 'Year': [year1, year2,year3],
'A': [200,300,400],
'B': [500,600,300],
'C': [450,369,235],
'A cost': [7000, 4000, 7000 ],
'B cost': [9000, 4000, 6000],
'C cost': [1100, 4300, 2320],
})
print(df)
current data frame:
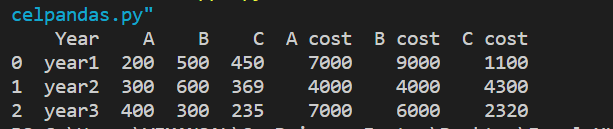
Desired data frame:
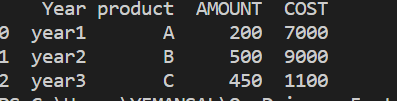
CodePudding user response:
Create MultiIndex by splitting columnsnames and setting Year to index, then replace missing values with amount and reshape by DataFrame.stack:
df = pd.DataFrame({ 'Year': 'year1,year2,year3'.split(','),
'A': [200,300,400],
'B': [500,600,300],
'C': [450,369,235],
'A cost': [7000, 4000, 7000 ],
'B cost': [9000, 4000, 6000],
'C cost': [1100, 4300, 2320],
})
print(df)
df1 = df.set_index('Year')
df1.columns = df1.columns.str.split(expand=True)
f = lambda x: 'amount' if pd.isna(x) else x
df1 = df1.rename(columns=f).stack(0).rename_axis(['Year','product']).reset_index()
print (df1)
Year product amount cost
0 year1 A 200 7000
1 year1 B 500 9000
2 year1 C 450 1100
3 year2 A 300 4000
4 year2 B 600 4000
5 year2 C 369 4300
6 year3 A 400 7000
7 year3 B 300 6000
8 year3 C 235 2320
CodePudding user response:
This can be achieved quite simply with janitor's pivot_longer:
# pip install janitor
import janitor
out = (df
.pivot_longer(index='Year', names_to=('product', '.value'),
names_pattern=r'(\S )\s*(\S*)')
.rename(columns={'': 'amount'})
)
output:
Year product amount cost
0 year1 A 200 7000
1 year2 A 300 4000
2 year3 A 400 7000
3 year1 B 500 9000
4 year2 B 600 4000
5 year3 B 300 6000
6 year1 C 450 1100
7 year2 C 369 4300
8 year3 C 235 2320