I have the following dataframe about trajectory, segment and the prediction results for an instance of such segment.
import pandas as pd
data = {'trajectory': [101,102,102,102,102,102,102,102,104,104,104,104,104,104,104,107,107,107,107,
107,107,107,107,107,108,108,108,108,108,108,108,109,109,109,109,109,109,112,
112,112,112,112,113,113,113,113,114,114,114,114],
'segment': [1,1,1,1,2,2,3,3,1,1,2,2,2,3,3,1,1,2,2,2,2,3,3,3,1,1,1,
2,2,2,2,1,1,1,2,2,2,1,1,2,2,2,1,2,2,3,1,2,2,2],
'prediction': [3,0,0,1,3,3,2,2,0,0,4,4,2,0,0,0,0,2,2,2,3,0,0,2,0,0,1,1,
1,1,0,1,2,1,3,3,3,1,1,4,4,2,1,4,4,3,0,3,3,2]}
df = pd.DataFrame(data)
df.head(10)
trajectory segment prediction
0 101 1 3
1 102 1 0
2 102 1 0
3 102 1 1
4 102 2 3
5 102 2 3
6 102 3 2
7 102 3 2
8 104 1 0
9 104 1 0
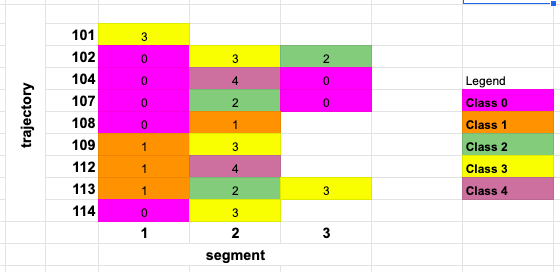
Now I want to produce a spectrogram of this data, plotting trajectory on the y-axis, and segment on the x-axis. In the following way.
- where there are multiple rows for a
trajectory(almost all), select only 1 row (uniquesegment) for thattrajectory. - the corresponding
predictionvalue of that row should be the majority value from the predictions of thatsegment. - attribute colour code to each prediction label (e.g.
0: blue,1: redetc..
Note: the trajectories do not have equal number of segments in all cases, depending on the length of the trajectory.
So in the given example, we should first resolve to a new dataframe df_new with the following entries:
df_new
trajectory segment prediction
0 101 1 3
1 102 1 0
2 102 2 3
3 102 3 2
4 104 1 0
5 104 2 4
6 104 3 0
7 107 1 0
8 107 2 2
9 107 3 0
10 108 1 0
11 108 2 1
12 109 1 1
13 109 2 3
14 112 1 1
15 113 2 4
16 113 3 4
17 114 1 0
18 114 2 3
Expected output:
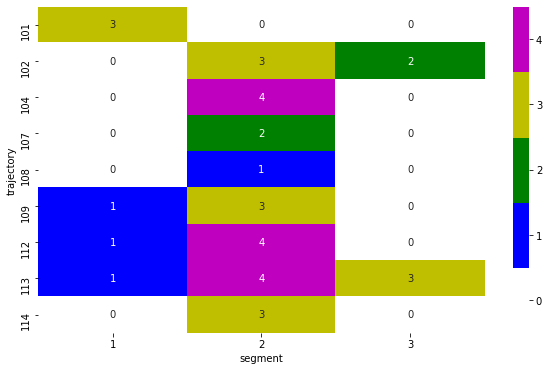
The expected spectrogram plot from this MWE is the figure below:
How to I achieve the target plot?
CodePudding user response:
There are quite a few things you're asking in this question. I'm just gonna post the code, you can play with it and modify the plot to your liking:
# calculate the data to plot
plot_data = (df.value_counts()
.sort_values(ascending=False)
.reset_index()
.drop_duplicates(['trajectory', 'segment'])
.pivot_table(index='trajectory', columns='segment', values='prediction', fill_value=0))
# create a discrete color map
import matplotlib.colors as mcolors
cmap = mcolors.ListedColormap(['w', 'b', 'g', 'y','m'])
bounds = [-0.5, 0.5, 1.5, 2.5, 3.5, 4.5]
norm = mcolors.BoundaryNorm(bounds, cmap.N)
# plot the data with the color map
fig, ax = plt.subplots()
fig, ax = plt.subplots(figsize=(10,6))
sns.heatmap(plot_data,
vmin=-0.5, vmax=4.5,
cmap=cmap, annot=True)
Output: