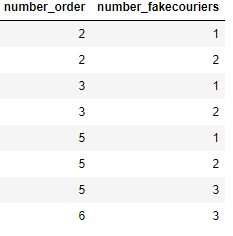
I have the following dataset that you can replicate with this code:
number_order = [2,2,3,3,5,5,5,6]
number_fakecouriers = [1,2,1,2,1,2,3,3]
dictio = {"number_order":number_order, "number_fakecouriers":number_fakecouriers}
actual_table = pd.DataFrame(dictio)
What I need is to write a code that through a for loop or a groupby generates the following result:
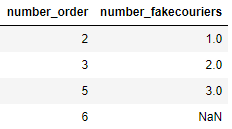
The code should perform a groupby on the column "number_orders" and then take the minimum of the column "number_fakeorders", but each time it should iteratively exclude the minimum values of the column "number_fakeorders" that have been already selected. Then in case there are no more values available it should input a "None".
This is the explanation row by row:
1) "number_orders" = 2 : here the value of "number_fakeorders" is "1", and it is simply the minimum value of "number_fakeorders", where ["number_orders" = 2], because it is the first value that appears
2) "number_orders" = 3 : here the value of "number_fakeorders" is "2" because "1" has been already selected for ["number_orders" = 2], so excluding "1", where ["number_orders" = 3] the minimum value is "2"
3) "number_orders" = 5 : here the value of "number_fakeorders" is "3" because "1" and "2" have been already selected
4) "number_orders" = 6 : here the value of "number_fakeorders" is "None" because the only value of "number_fakeorders" where ["number_orders" = 6] is "3", and "3" has already been selected
CodePudding user response:
Try:
def fn(x, seen):
for v in x:
if v in seen:
continue
seen.add(v)
return v
out = (
actual_table.groupby("number_order")["number_fakecouriers"]
.apply(fn, seen=set())
.reset_index()
)
print(out)
Prints:
number_order number_fakecouriers
0 2 1.0
1 3 2.0
2 5 3.0
3 6 NaN
Note: You can sort dataframe before processing (if not sorted already):
actual_table = actual_table.sort_values(
by=["number_order", "number_fakecouriers"]
)
...
CodePudding user response:
Loop the groupby object and record previous min value in each group
res, prev_min = [], set()
for name, group in actual_table.groupby('number_order'):
diff = set(group['number_fakecouriers']).difference(prev_min)
if len(diff):
m = min(diff)
prev_min.add(m)
else:
m = np.nan
res.append([name, m])
out = pd.DataFrame(res, columns=actual_table.columns)
print(out)
number_order number_fakecouriers
0 2 1.0
1 3 2.0
2 5 3.0
3 6 NaN