I have a parquet file in my disk. I am reading the disk using spark. All I wanted is the data to be in the readable and understandable form. But due to more number of columns the columns are shifted downward and the data seems like they are shuffled and its hard to read the data. My expectation is when data are displayed:
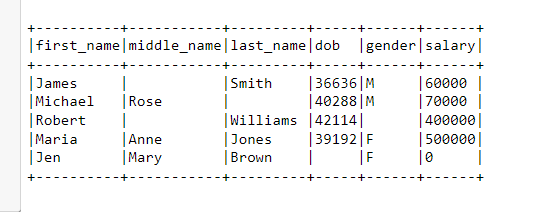
But in my case I am using:
df2=spark.read.parquet("D:\\source\\202204121921-seller_central_opportunity_explorer_niche_search_term_metrics.parquet")
df2.show()
I am getting the data in unstructured way when using show() function. I want them in rows and columns so they can be in readable form.
My spark is: 2.4.4
IDE: Juypter Notebook
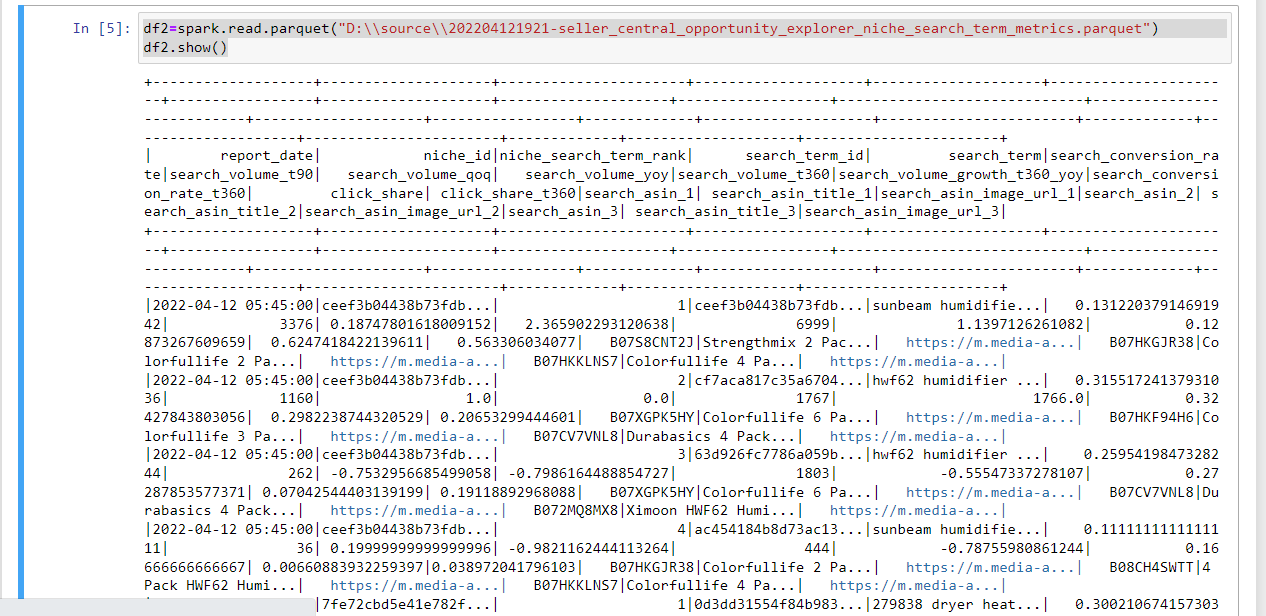
How can I make this structure so data can be in readable form?
CodePudding user response:
This might be helpful:
Disable the truncate option while you run show:
How to show full column content in a Spark Dataframe?
More info: https://spark.apache.org/docs/3.1.3/api/python/reference/api/pyspark.sql.DataFrame.show.html
DataFrame.show(n=20, truncate=True, vertical=False)
Prints the first n rows to the console.New in version 1.3.0.
Parameters:
nint, optional
Number of rows to show.
truncatebool, optional
If set to True, truncate strings longer than 20 chars by default. If set to a number greater than one, truncates long strings to length truncate and align cells right.
verticalbool, optional
If set to True, print output rows vertically (one line per column value).
Enable the scroll for the output:
https://www.youtube.com/watch?v=U4usAUZCv_c