Having a data set as below:
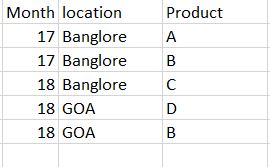
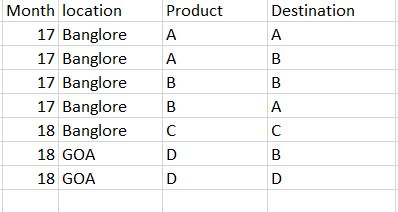
I need to do the cartesian of product based on month and location. Need an output as below:
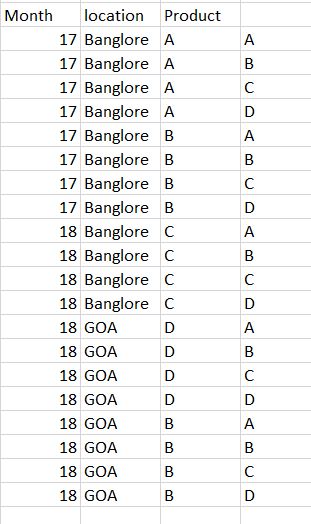
I created a new dataframe-with the unique values of product. Then cross merged the df with dataset.need to drop the rows based on the month,location and product
CodePudding user response:
You can use itertools.product:
prods = [list(product(df[df.Month == month].location, df[df.Month == month].Product)) for month in df.Month.unique()]
Note that then I applied itertools.chain to prods as to 'flatten' it as it is a nested list,
prods = list(chain(*prods))
month_prod = [[m for i in range(len(df[df.Month == m]))] for m in df.Month]
months = list(chain(*month_prod))
df = pd.DataFrame({'Month': months, 'location': [item[0] for id, item in enumerate(prods)], 'Product': [item[1] for id, item in enumerate(prods)]} )
CodePudding user response:
You can try groupby then cross merge on Product column
out = (df.groupby(['Month', 'Location'])
.apply(lambda g: g[['Product']].merge(g[['Product']], how='cross'))
.droplevel(2)
.reset_index()
.rename(columns={'Product_x': 'Product', 'Product_y': 'Destination'}))
print(out)
Month Location Product Destination
0 17 Banglore A A
1 17 Banglore A B
2 17 Banglore B A
3 17 Banglore B B
4 18 Banglore C C
5 18 GOA D D
6 18 GOA D B
7 18 GOA B D
8 18 GOA B B