import torch
import torch.nn as nn
import os
class Net(nn.Module):
def __init__(self):
super().__init__()
self.h = -1
def forward(self, x):
self.h =x
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
if torch.cuda.is_available():
print('using Cuda devices, num:', torch.cuda.device_count())
model = nn.DataParallel(Net())
x = 2
print(model.module.h)
model(x)
print(model.module.h)
When I use multiple GPUs to train my model, I find that the Net's params can't be updated correctly, it remains the initial value. However, when I use only one GPU instead, it's can be correctly updated. How can I fix this problem? thx! (The examples are posted in the image)
This is when I using two GPUs, the param 'h' didn't change:
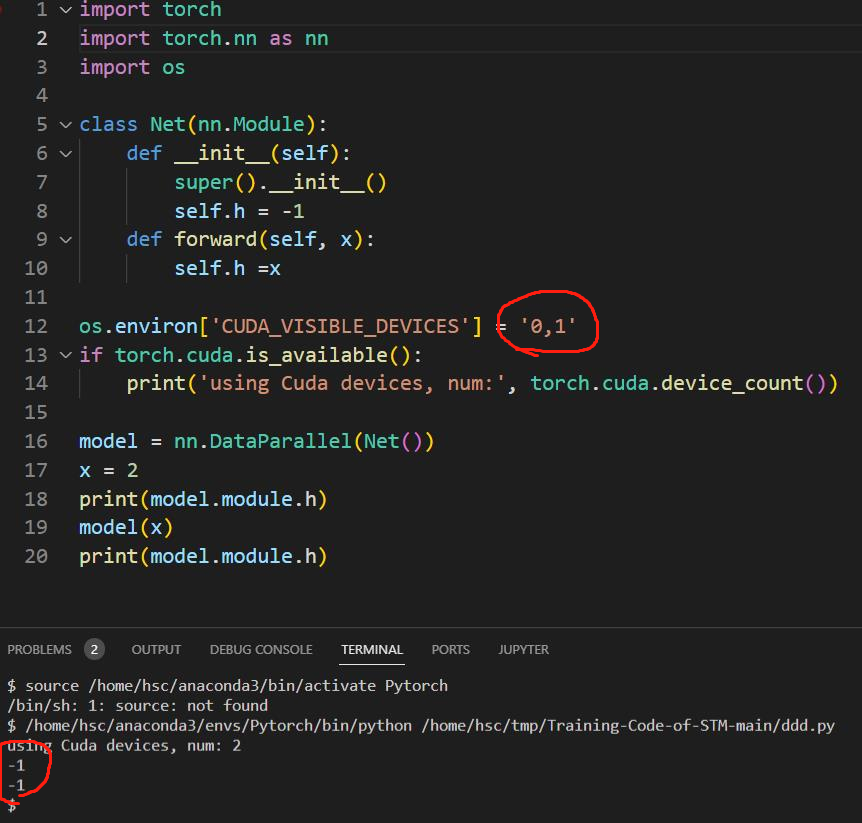
This is when I using only one GPU, the param 'h' had changed:
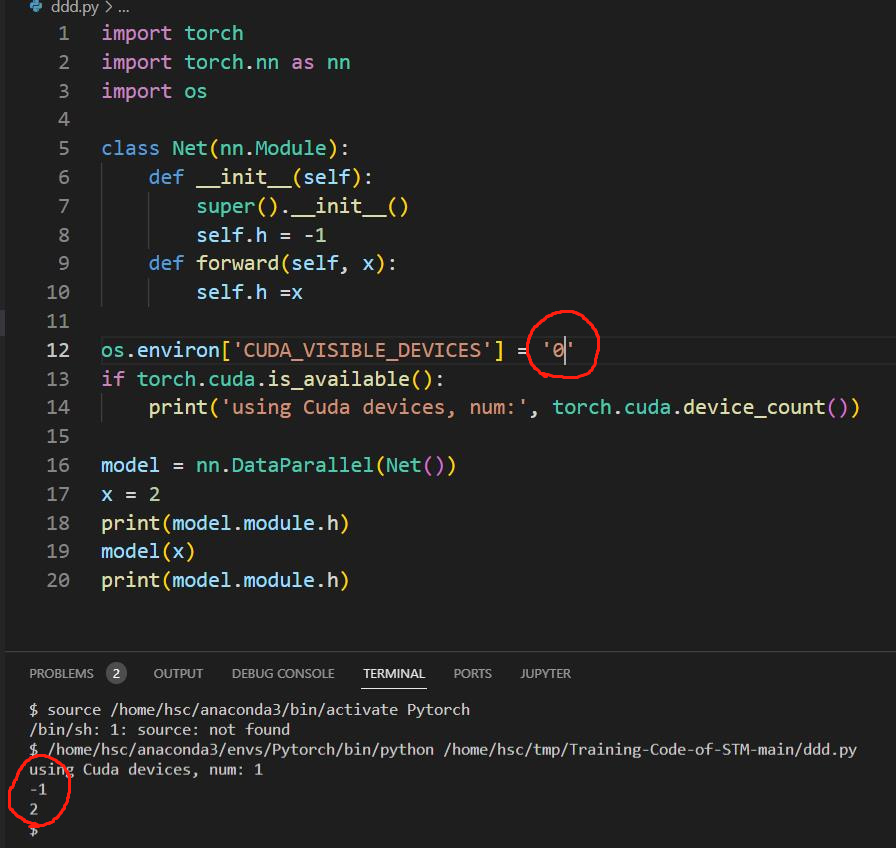
CodePudding user response:
From the PyTorch's documentation (https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html):
In each forward,
moduleis replicated on each device, so any updates to the running module inforwardwill be lost. For example, ifmodulehas a counter attribute that is incremented in each forward, it will always stay at the initial value because the update is done on the replicas which are destroyed afterforward.
I am guessing PyTorch skips the copying part when there is only one GPU.
Also, your h is just an attribute. It is not a "parameter" in PyTorch.