this is my code
import pandas as pd
f = open("G:\WNBA\wnba_id.txt", "r")
print(f)
for id in f:
matchid.append(id)
_url_template = "https://www.basketball-reference.com/wnba/boxscores/{}"
for x in matchid:
formatted_url = _url_template.format(x)
print(formatted_url)
df=pd.read_html(formatted_url, match='(Q1)')
for i in df:
new=i.assign(match_id=x)
new.to_csv("G:\WNBA\wnba_Q1.csv", mode='a', header=False)
I get this error: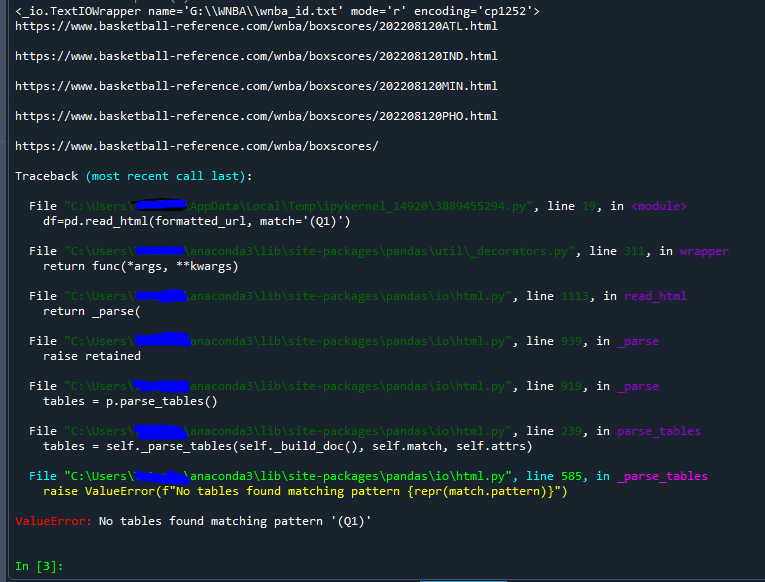
It worked fine till 2 weeks ago...now the problem is that the script works, i don't know why i get this error because the table Q1 exist and it's properly imported into my csv file; the only problem is that sincei want to add some other scraping line after this in the same file, getting the error it is got stopped and i've to launch individually every other script (specifing that they work but they all give the same error as this one i posted). Any clue to get rid of this error?
Thank you!
CodePudding user response:
Could this be due to the syntax used to match? Does
df=pd.read_html(formatted_url, match='Q1')
work? As brackets aren't needed to match something with read_html(). panda Docs.
CodePudding user response:
Your issue is with:
f = open("G:\WNBA\wnba_id.txt", "r")
print(f)
for id in f:
matchid.append(id)
At some point in your txt file, it's appending an empty string.
How do I know?
You did a good thing here by including the print(formatted_url). We can see exactly at what point in your code it breaks. Looking at your console output, we see:
https://www.basketball-reference.com/wnba/boxscores/202208120ATL
https://www.basketball-reference.com/wnba/boxscores/202208120MIN
https://www.basketball-reference.com/wnba/boxscores/202208120PHO
This is followed by:
https://www.basketball-reference.com/wnba/boxscores/
, meaning there is an empty string going into "https://www.basketball-reference.com/wnba/boxscores/{}"
So take a look at that file, and see what's after '202208120PHO'
You can also fix this in the code, by not appending empty strings into the matchid list.
f = open("G:\WNBA\wnba_id.txt", "r")
print(f)
for id in f:
if id.strip() != '':
matchid.append(id)