I am running this code to create the DF included in the picture below:
library(tidyverse)
library(espnscrapeR)
steelers_data <- espnscrapeR::get_nfl_pbp(401326308) %>%
group_by(drive_id) %>%
janitor::clean_names() %>%
dplyr::rename(
posteam = pos_team_abb,
qtr = drive_start_qtr,
desc = play_desc) %>%
select(game_id, drive_id, posteam, play_id, play_type, yards_gained, desc,
logo, qtr, drive_result, home_team_abb, away_team_abb, home_wp) %>%
mutate(home_wp = dplyr::lag(home_wp, 1)) %>%
mutate(away_wp = 1.00 - home_wp) %>%
filter(posteam == "PIT") %>%
filter(!play_type %in% c("Kickoff", "End Period", "End of Half", "Timeout", "Kickoff Return (Offense)", "End of Game"))
##testing
testing <- steelers_data %>%
filter(drive_id == "4013263082") %>%
group_by(play_id) %>%
summarize(wp_data = list(away_wp), .groups = "drop")
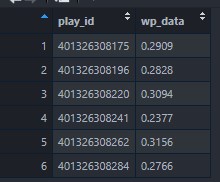
However, I would like to add the next row's wp_data to the prior. My desired output is this:
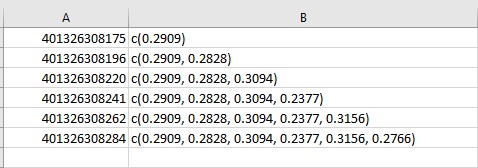
Any help is greatly appreciated.
CodePudding user response:
Use purrr::accumulate:
library(tidyverse)
data.frame(A = 1:10) %>%
mutate(A2 = purrr::accumulate(A, c))
or Reduce:
df <- data.frame(A = 1:10)
df$A2 <- Reduce(c, df$A, accumulate = T)
output
A A2
1 1 1
2 2 1, 2
3 3 1, 2, 3
4 4 1, 2, 3, 4
5 5 1, 2, 3, 4, 5
6 6 1, 2, 3, 4, 5, 6
7 7 1, 2, 3, 4, 5, 6, 7
8 8 1, 2, 3, 4, 5, 6, 7, 8
9 9 1, 2, 3, 4, 5, 6, 7, 8, 9
10 10 1, 2, 3, 4, 5, 6, 7, 8, 9, 10