I have a Python code and a C code.
My Python code is this:
import os
import time
count = 0
number_of_itration =100000000
begin = time.time()
for i in range(number_of_itration):
count = 1
end = time.time()
print(f'Sum is {count}')
print(f"Total runtime of the program is {end - begin} Seconds")
This code takes 12 seconds to execute.
I have a similar C Code:
int main (int argc, char *argv[])
{
if (InitCVIRTE (0, argv, 0) == 0)
return -1;
start_t = clock();
for(i=0; i< 100000000; i )
{
count= count 1;
}
end_t = clock();
total_t = (double)(end_t - start_t) / CLOCKS_PER_SEC;
printf("Total time taken by CPU: %f\n", total_t );
RunUserInterface ();
return 0;
}
This takes 0.395 seconds.
And I have a labview code:
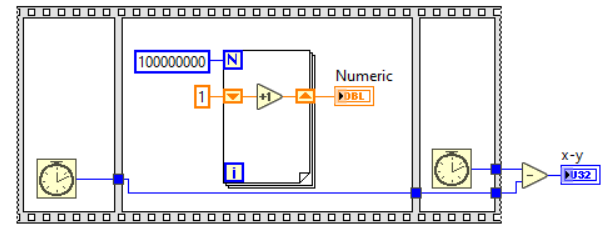
Which takes just 0.093 seconds.
Where am I going wrong? I was expecting C to run faster.
My C IDE is Lab windows CVI, which is from National Instruments.
My system configuration is:
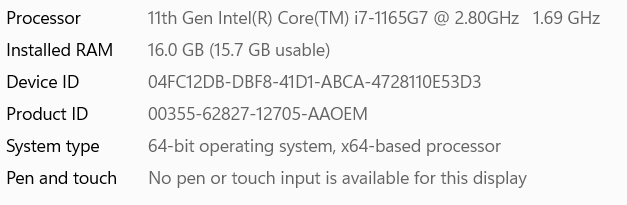
How can I optimize C code for processor?
CodePudding user response:
I could optimize my C code and i found that the C code could execute the same in 50 Milli seconds in release mode
where lab view takes 93 milliseconds
but in Python i could int fine anything similar to release more or anything
CodePudding user response:
If you have debugging turned off, LabVIEW will constant fold that For Loop during compilation. It won't take any time at all to execute because it'll all reduce to a single pre-computed constant value. Change the input to the For Loop's shift register from a constant to a control and add the control to the connector pane. You should see the time increase to be about equal to the C code. I suspect if you change your compile options on the C code, you'd see the time there decrease.
Python doesn't do those kinds of optimizations.