I am working with a large data set containing portfolio holdings of clients per date (i.e. in each time period, I have a number of stock investments for each person). My goal is to try and identify 'buys' and 'sells'. A buy happens when a new stock appears in a person's portfolio (compared to the previous period). A sell happens when a stock disappears in a person's portfolio (compared to the previous period). Is there an easy/efficient way to do this in Python? I can only think of a cumbersome way via for-loops.
Suppose we have the following dataframe:
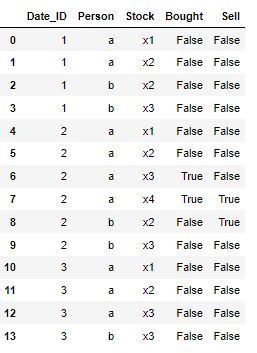
which can be computed with the following code:
df = pd.DataFrame({'Date_ID':[1,1,1,1,2,2,2,2,2,2,3,3,3,3], 'Person':['a', 'a', 'b', 'b', 'a', 'a', 'a', 'a', 'b', 'b', 'a', 'a', 'a', 'b'], 'Stock':['x1', 'x2', 'x2', 'x3', 'x1', 'x2', 'x3', 'x4', 'x2', 'x3', 'x1', 'x2', 'x3', 'x3']})
I would like to create the 'bought' and 'sell' columns which identify stocks that have been added or are going to be removed from the portfolio. The buy column equals 'True' if the stock newly appears in the persons portfolio (compared to the previous date). The Sell column equals True in case the stock disappears from the person's portfolio the next date.
How to accomplish this (or something similar to identify trades efficiently) in Python?
CodePudding user response:
You can group your dataframe by 'Person' first because
people are completely independent from each other.
After that, for each person - group by 'Date_ID', and for each stock in a group determine if it is present in the next group:
def get_person_indicators(df):
"""`df` here contains info for 1 person only."""
g = df.groupby('Date_ID')['Stock']
prev_stocks = g.agg(set).shift()
was_bought = g.transform(lambda s: ~s.isin(prev_stocks[s.name])
if not pd.isnull(prev_stocks[s.name])
else False)
next_stocks = g.agg(set).shift(-1)
will_sell = g.transform(lambda s: ~s.isin(next_stocks[s.name])
if not pd.isnull(next_stocks[s.name])
else False)
return pd.DataFrame({'was_bought': was_bought, 'will_sell': will_sell})
result = pd.concat([df, df.groupby('Person').apply(get_person_indicators)],
axis=1)
Note:
For better memory usage you can change the dtype of the 'Stock' column from str to Categorical:
df['Stock'] = df['Stock'].astype('category')