I have a table with position (junior, senior), salary, and an ID. I have done the following to find the highest salary for each position.
SELECT position, MAX(salary) FROM candidates GROUP BY position;
What I am getting:

How I want it:
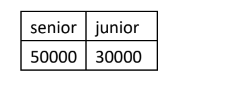
I want to transpose the outcome so that 'junior' and 'senior' are the columns without using crosstab. I have looked at many pivot examples but they are done on examples much more complex than mine.
CodePudding user response:
Here is my attempt at teaching myself crosstab:
CREATE EXTENSION IF NOT EXISTS tablefunc;
select Junior
, Senior
from
(
select *
from crosstab
(
'select 1, position, max(salary)
from candidates
group by position
'
, $$VALUES('Junior'), ('Senior')$$
)
as ct(row_number integer, Junior integer, Senior integer) --I don't know your actual data types, so you will need to update this as needed
) q
Edit: Below is no longer relevant as this appears to be PostgreSQL
Based on your description, it sounds like you probably want a pivot like this:
select q.*
from
(
select position
, salary
from candidates
) q
pivot (
max(salary) for position in ([Junior], [Senior])
) p
This example was made in SQL Server since we don't know DBMS.
CodePudding user response:
I am not proficient in PostgreSQL, but I believe there is a practical workaround solution since this is a simple table:
SELECT
max(case when position = 'senior' then salary else null end) senior,
max(case when position = 'junior' then salary else null end) junior
FROM payments
It worked with this example:
create table payments (id integer, position varchar(100), salary int);
insert into payments (id, position, salary) values (1, 'junior', 1000);
insert into payments (id, position, salary) values (1, 'junior', 2000);
insert into payments (id, position, salary) values (1, 'junior', 5000);
insert into payments (id, position, salary) values (1, 'junior', 3000);
insert into payments (id, position, salary) values (2, 'senior', 3000);
insert into payments (id, position, salary) values (2, 'senior', 8000);
insert into payments (id, position, salary) values (2, 'senior', 9000);
insert into payments (id, position, salary) values (2, 'senior', 7000);
insert into payments (id, position, salary) values (2, 'senior', 4000);
select
max(case when position = 'junior' then salary else 0 end) junior,
max(case when position = 'senior' then salary else 0 end) senior
from payments;
CodePudding user response:
It depends on which SQL dialect you are running. It also depends on the complexity of your table. In SQL Server, I believe you can use the solutions provided in this question for relatively simple tables: Efficiently convert rows to columns in sql server