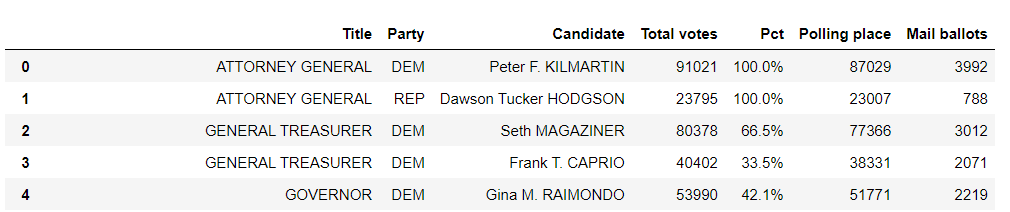
Beginner working with python and beautiful soup, attempting to scrape election results data from a state elections page. Went by the book 'learning to code with baseball' to learn all of my basics, including the 5th chapter which covers scraping.
I am working on scraping one table from the site, which looks like this:
| Candidate | Total Votes | Pct |
|---|---|---|
| Abraham Lincoln | 53990 | 42.1% |
| George Washington | 37326 | 29.1% |
After using BeautifulSoup to read the entire site and identify the tables. I was successful in isolating this table from the rest of the tables on the site and identifying the header row using:
gov_table = tables[3]
rows = gov_table.find_all('tr')
header_row = rows[0]
The trouble i ran into was with the data rows. I cannot seem to pick up the candidate's names, only their 'total votes' and 'pct'.
I try:
first_data_row = rows[1]
first_data_row.find_all('td')
which gives the HTML:
[<td data-title="Candidate" scope="row">ABRAHAM LINCOLN <span >(DEM)</span> </td>,
<td width="25%">
<ul >
<li>Polling place: 51771</li>
<li>Mail ballots: 2219</li>
</ul>
</td>,
<td data-title="Total votes">53990</td>,
<td data-title="Pct">42.1%</td>]
I then attempt to run a comprehension on all the td tags to isolate them in a list, which I will use as the rows to a DataFrame. But the trouble I have is, I cannot seem to pick up the candidates name:
In [82]: [str(x.string) for x in first_data_row.find_all('td')]
Out[82]: ['None', 'None', '53990', '42.1%']
I'm really stumped about the 'None' strings as they dont appear anywhere in the table rows themselves. I have tried narrowing in on it further using
In [83]: [str(x.string) for x in first_data_row.find_all('td', {'scope': 'row'})]
Out[83]: ['None']
or
In[87]: first_candidate_name = first_data_row.find_all('td')[0]
...first_candidate_name
...str(first_candidate_name.string)
Out[87]: 'None'
With similar results.
I am sure I am missing something relatively minor but my beginning eyes can't narrow it down. Please help!!
CodePudding user response:
You're using .string to access the content within the rows, and some of these rows have multiple children, which means .string will return None
On the other hand, .get_text() returns all the strings of the children concatenated into one string
> [str(x.string) for x in first_data_row.find_all('td')]
> ['None', 'None', '53990', '42.1%']
> [str(x.get_text()) for x in first_data_row.find_all('td')]
> ['Gina M. RAIMONDO (DEM) ', '\n\nPolling\xa0place:\xa051771\nMail\xa0ballots:\xa02219\n\n', '53990', '42.1%']
From the