My current project deals with writing data from one excel file to a specific format, chosen by the user. The format is saved in a folder as excel file where headers and some other text (which will always stay the same) is already in the file, and the only thing that needs to be done is to fill the file with data.
For this I would like to "simply" insert my pandas dataframe at a certain row, so that neither the header nor the footer will be overwritten.
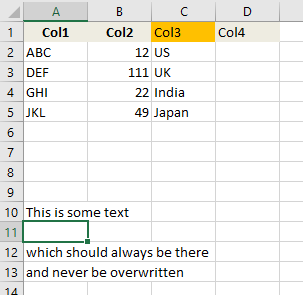
Here an example format:
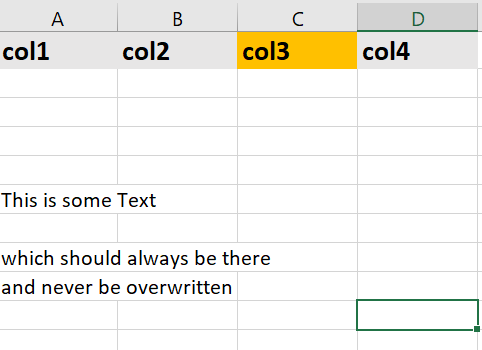
And how I want the result to look like:
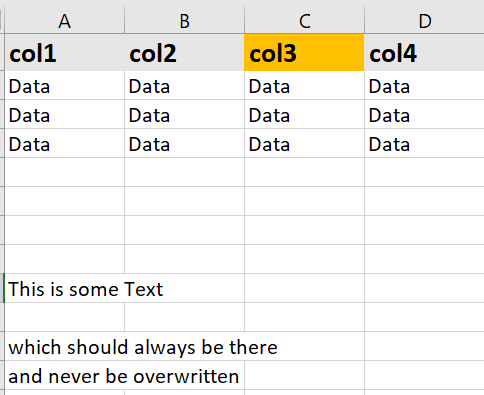
I already managed to write the data to the file below the header row, but it overwrites the footer. This is the code that does exactly that:
fileName = saveFolder "test.xlsx"
shutil.copyfile(format_path, fileName)
book = load_workbook(fileName)
writer = pd.ExcelWriter(fileName, engine='openpyxl')
writer.book = book
writer.sheets = {ws.title: ws for ws in book.worksheets}
df.to_excel(writer, sheet_name="Tabelle1", startrow=1)
writer.close()
If this is not possible the only workaround I can think of is to read the format used, save it in python, write the header in the given format (background colour, fontsize,...), then the data, and then the footer.
However, if I remember correctly when reading text python will not remember which words are written in bold, and which words are normal. If someone, however, knows how to do this, I would also very much appreciate comments that try to solve my issue in that direction.
CodePudding user response:
To preserve the existing format, etc. you will need insert data into specific cells and openpyxl will allow you to do that. to_excel() will overwrite the worksheet you are trying to add the data. There are some gaps in the question, but I will try to answer it the best I can. Below is the code which will:
- Assume there is a dataframe existing with a few rows of data
- The program will open the template file (like in the screen shot shared)
- Add that dataframe (insert rows and add data without header) to the file (screen shot shared)
- Save it as a new file
- I am assuming there is just one sheet in template and you are writing to that. You can use for loops to add more sheets or new files
Note that the new rows of data will need to be inserted so that the footer will move down and NOT get deleted. The format, color, etc. of the template will remain intact.
dataframe df (including header)
Name Age Nationality
ABC 12 US
DEF 111 UK
GHI 22 India
JKL 49 Japan
Code
import openpyxl
from openpyxl.utils.dataframe import dataframe_to_rows
file = 'inputfile.xlsx' ## Your template file
wb = openpyxl.load_workbook(filename=file)
ws = wb.active ## You can ws = wb['Sheet1'] if you want to specify a specific sheet
ws.insert_rows(idx=2, amount=len(df)) ## Insert as many rows as in df (4 in our case) after row 1
rows = dataframe_to_rows(df, index=False, header=None)
for r_idx, row in enumerate(rows, 2):
for c_idx, value in enumerate(row, 1):
ws.cell(row=r_idx, column=c_idx, value=value) ##Add the data
wb.save('NewFile.xlsx') ##Your output file
Template (inputfile.xlsx)
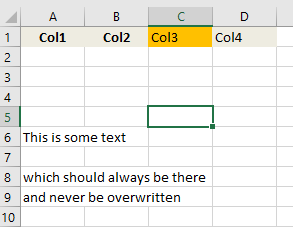
Output (Newfile.xlsx)