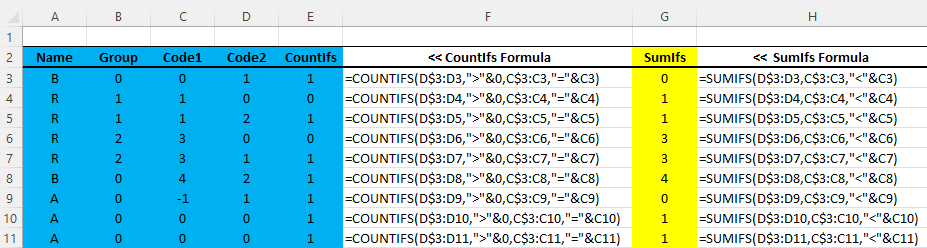
In the below reproducible code, I would like to add a column for SumIfs using dplyr as detailed in the below image, whereby the Excel sumifs() formula in column H of the image has conditions with the tops of the specified ranges "anchored", for a "rolling" calculation as you move down row-wise. Any recommendations for how to do the same in dplyr? I'm sure it requires grouping but unsure of how to handle conditions. The blue below shows the current reproducible code output, the yellow shows what I would like to add, and the non-highlighted shows the underlying XLS formulas.
Now using my words: to derive Sumifs, for each row one-at-a-time rolling from top-to-bottom of the array sequentially, sum all values in column D from the top of the column D range to the current row in the Column D range that have a column C "Code1" value less than the current row column C "Code1" value. So for example in deriving the value of 3 in cell G6: add the 1 in cell D3 (because its Code1 of 0 (cell C3) is < Code1 of 3 (cell C6)) to the 2 in cell D5 (because its Code1 of 1 (cell C5) is < Code1 of 3 (cell C6)).
Reproducible code:
library(dplyr)
myData <-
data.frame(
Name = c("B","R","R","R","R","B","A","A","A"),
Group = c(0,1,1,2,2,0,0,0,0),
Code1 = c(0,1,1,3,3,4,-1,0,0),
Code2 = c(1,0,2,0,1,2,1,0,0)
)
CountIfs <- function(x,y) {
out <- integer(length(x))
for(i in seq_along(x)) {
cond1 <- y[1:i] > 0
cond2 <- x[1:i] == x[i]
out[i] <- sum(cond1*cond2)
}
out
}
myDataRender <-
myData %>%
mutate(CountIfs = CountIfs(Code1, Code2))
print.data.frame(myDataRender)
Adapt Tsai solution for situations where the top/bottom of the XLS sumifs() ranges are anchored (fixed, not rolling)(where first XLS formula in the image would be =SUMIFS(D$3:D$11,C$3:$C11,"<"&C3)), for those of us transitioning from XLS to R:
myData %>% mutate(SumIfs = sapply(1:n(), function(x) sum(Code2[1:n()][Code1[1:n()] < Code1[x]])))
CodePudding user response:
You could use map() or imap() from purrr:
library(dplyr)
library(purrr)
# (1)
myData %>%
mutate(SumIfs = map_dbl(1:n(), ~ sum(Code2[1:.x][Code1[1:.x] < Code1[.x]])))
# (2)
myData %>%
mutate(SumIfs = imap_dbl(Code1, ~ sum(Code2[1:.y][Code1[1:.y] < .x])))
# Name Group Code1 Code2 SumIfs
# 1 B 0 0 1 0
# 2 R 1 1 0 1
# 3 R 1 1 2 1
# 4 R 2 3 0 3
# 5 R 2 3 1 3
# 6 B 0 4 2 4
# 7 A 0 -1 1 0
# 8 A 0 0 0 1
# 9 A 0 0 0 1
If you don't want to rely on purrr, the map() solution can be adapted directly for the base sapply() version:
myData %>%
mutate(SumIfs = sapply(1:n(), \(x) sum(Code2[1:x][Code1[1:x] < Code1[x]])))
CodePudding user response:
Here is another way using map2_dbl() with the row number.
library(dplyr)
library(purrr)
myData %>%
mutate(SumIfs = map2_dbl(Code1, row_number(),
~ sum(if_else(Code1 < .x & row_number() <= .y, Code2, 0))))
Also using base Map(), this will scale to as many criteria as you want.
library(dplyr)
myData %>%
mutate(SumIfs = unlist(Map(\(x, y) sum(if_else(Code1 < x & row_number() <= y, Code2, 0)),
Code1, row_number())))