I have the following dataframe:
Country Employee ID Location
CZ 1 WAREHOUSE
CZ 2 Warehouse
CZ 3 PlaNt
CZ 4 Car
DK 5 Car
DK 7
ES 7 *
ES 8 Técnico
ES 3 Rádio
I need to search for the values added in "Location" column in the dataframe below (not considering if the value is capslock or not and disconsidering special non english characters punctuation such as in the example) considering its country and:
- if the "Location" value exists in that country on second dataframe, replace for that value.
- if the "Location" value do not exist in that country on second dataframe, replace for the first value of the second dataframe
- Create a column named "Legacy Location" that, if "Location" was replaced, add previous Location Name to that column. if Location was not replaced, leave column blank. And, if "Location" was blank when doing the comparison, add the string "blank" to "Legacy Location" column.
This is the lookup dataframe:
Country Location name
CZ Warehouse
CZ Plant
DK Car
DK Plant
DK Warehouse
ES Tecnico
ES Rádio
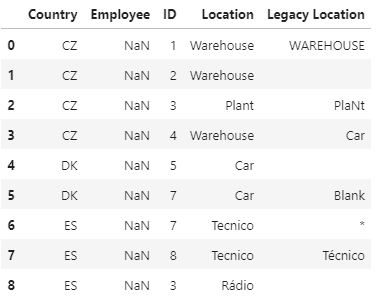
And that is the expected output:
Country Employee ID Location Legacy Location
CZ 1 Warehouse WAREHOUSE
CZ 2 Warehouse
CZ 3 Plant PlaNt
CZ 4 Warehouse Car
DK 5 Car
DK 7 Car Blank
ES 7 Tecnico *
ES 8 Tecnico Técnico
ES 3 Rádio
What is the best way to achieve this result?
Thank you so much!
CodePudding user response:
Considering that df is the first dataframe and lookup_df is the lookup one, use this :
import numpy as np
import pandas as pd
out = df.merge(lookup_df, on='Country', how='left')
out['Location_v2'] = out.apply(lambda x: x['Location name'][0] if str(x['Location']).title() not in x['Location name'] else str(x['Location']).title(), axis=1)
out['Legacy Location'] = np.where(out['Location'].isna(), 'Blank',
np.where(out['Location'] != out['Location_v2'], out['Location'], ''))
out = out.drop(['Location name', 'Location'], axis=1)
out.rename(columns = {'Location_v2':'Location'}, inplace = True)
>>> print(out)