In the script below, I try to get the values stored in the first column and the second column of the second row of a csv file.
For instance for the csv data below:
Appel, 21,high,yes
Pear, 23, high, no
Ananas, 14, low, no
With the code below, I would like to get in the results the information "Pear" and "23" store in the column 1 and column2 of the second row.
import csv
with open ("data.csv", "r") as source:
reader = csv.reader(source)
data = []
for row in reader:
data.append(row)
result1 = data[2] [1]
result2 = data[2] [2]
print (result1, result2)
To be able to do this, I first initialize data to an empty list. Then, I set the first iteration through the loop. I append row, which is a list. But when I execute
result1 = data[2][1]
result2 = data[2][2]
I gest the error message Index Error: list index out of range.This is probably due to the fact that data is currently a list of length 1. But I do not know how to change code above. Can you please help me or give me some advice to solve this problem
CodePudding user response:
I'm going to assume your csv file has the format like this screenshot below. Here are 2 solutions, one using your current logic and one that uses pandas.
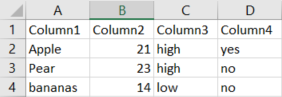
- reading files by line:
'''
with open('help.csv', 'r') as source:
for row_number, row in enumerate(source.readlines()):
if row_number == 0:
continue
else:
data = row.split(',')
result1 = data[0]
result2 = data[1]
print(result1, result2)
'''
this is what the data variable looks like:
['Apple', '21', 'high', 'yes\n']
['Pear', '23', 'high', 'no\n']
['bananas', '14', 'low', 'no\n']
- The former just uses standard Python and assumes your spreadsheet has column headers. You can avoid the if statement if you don't have headers.
- If it's a new concept, enumerate keeps track of which run in the for loop you are (since we are reading rows, this acts as which row in the spreadsheet).
- Since you are using a .csv file, using .split(',') will separate each row by the comma (column).
- watch out for the new-line character in the yes/no column -- you can call data[3].strip()
- This method works well if your original data doesn't change - meaning if you don't change the column format, but it becomes rather slow as the amount of data increases.
2.) using Pandas
- Pandas is a great tool for tabular (row/columns) data like excel.
- it is exponentially faster than looping through rows
if you know that you want pears (or other fruit in column 1)
read in the file, state the fruit you want data on
"slice" the data to get all cases where the fruit occurs in column1
get the value in the column we want
'''
import pandas as pd
df = pd.read_csv("data.csv", headers=True) # make false if no headers
fruit = 'Pear'
data = df[df['Column1']==fruit] # gets all rows with this fruit
result2 = data['Column2'].values[0] # gets value in relevant column
print(fruit, result2)
'''
- above assumes we only have one case of the fruit Pear, so call values[0]
- can call 0 > n if multiple cases of the fruit
case where we know a row index and want to see the data
'''
import pandas as pd
df = pd.read_csv("data.csv", headers=True) # make false if no headers
row_number = 1
row = df.iloc[row_number,:]
print(row['Column1'], row['Column2']
''''
CodePudding user response:
de-dent the last three lines so that they are not in the for loop.
import csv
with open ("data.csv", "r") as source:
reader = csv.reader(source)
data = []
for row in reader:
data.append(row)
result1 = data[2] [1]
result2 = data[2] [2]
print (result1, result2)
Or
with open ("data.csv", "r") as source:
reader = csv.reader(source)
data = []
for row in reader:
data.append(row)
result1 = data[2] [1]
result2 = data[2] [2]
print (result1, result2)
If you only need the information from the second line, you don't have to iterate over the whole file.
with open ("data.csv", "r") as source:
reader = csv.reader(source)
_ = next(reader) # throw the first line away
_ = next(reader) # throw this blank line away
result1, result2, *_ = next(reader)
print (result1, result2)