I have a large matrix, in which every row corresponds to a sample, and samples belong to a population. For example, the row name s1-2 means population 1 - sample 2. I would like to calculate the mean for every population, such as in the illustration (unfortunately, I cannot create a sample):
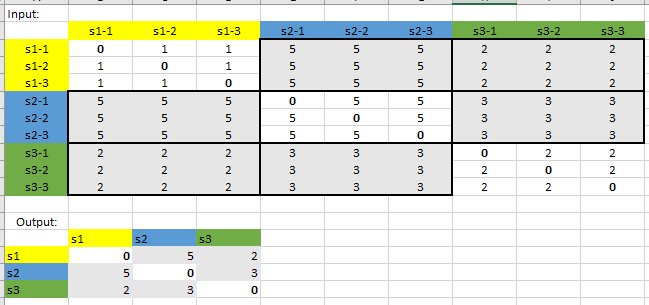
Is this possible in R? May I kindly ask for guidance?
CodePudding user response:
It's not clear why you can't create a sample. Here's one for the purposes of exposition:
set.seed(1)
dimnames <- paste(rep(paste0('s', 1:3), each = 3), rep(1:3, 3), sep = '-')
m <- matrix(sample(0:5, 81, TRUE), 9, dimnames = list(dimnames, dimnames))
m
#> s1-1 s1-2 s1-3 s2-1 s2-2 s2-3 s3-1 s3-2 s3-3
#> s1-1 0 2 4 5 5 3 4 3 3
#> s1-2 3 0 4 0 3 0 1 5 4
#> s1-3 0 4 0 3 3 5 5 2 4
#> s2-1 1 4 0 0 3 1 5 0 3
#> s2-2 4 1 5 3 1 2 5 3 5
#> s2-3 2 5 4 2 3 1 0 4 4
#> s3-1 5 5 4 5 0 5 2 0 3
#> s3-2 1 1 1 1 5 5 2 0 3
#> s3-3 2 0 1 1 0 1 5 5 0
To get the mean of each row / column group, then assuming we can identify the group by the first two characters of the row or column name (as in your example), we could do:
groups <- expand.grid(row = unique(substr(rownames(m), 1, 2)),
col = unique(substr(colnames(m), 1, 2)))
m2 <- matrix(unlist(Map(function(r, c) {
mean(m[grep(r, rownames(m)), grep(c, rownames(m))])
}, r = groups$row, c = groups$col)), 3,
dimnames = list(unique(substr(rownames(m), 1, 2)),
unique(substr(colnames(m), 1, 2))))
Resuting in
m2
#> s1 s2 s3
#> s1 1.888889 3.000000 3.444444
#> s2 2.888889 1.777778 3.222222
#> s3 2.222222 2.555556 2.222222