I have a piece a code which works nicely to sequentially order days between Plan_Start variable.
Setup code:
tx1 = pd.DataFrame({'Patient':[123,456,789,789,101],
'Plan':['Drug1','Drug43','Drug_abc','Drug_xyz','Drug_324'],
'Plan_Start':['4/21/2021','6/11/2021','7/7/2021','7/12/2021','9/20/2021'],
'Plan_End':['1/1/2030','7/20/2021','7/12/2022','7/31/2021','9/20/2022']})
tx1['Plan_Start'] = pd.to_datetime(tx1['Plan_Start'])
tx1['Plan_End'] = pd.to_datetime(tx1['Plan_End'])
tx1
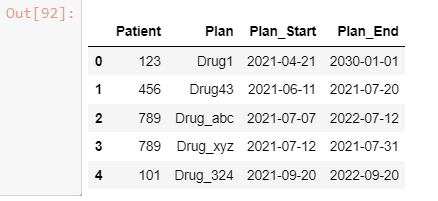
Which when you run the following code:
tx1.set_index('Plan_Start').groupby(['Patient']).resample('D').ffill().reset_index(level=0, drop=True).reset_index()
Produces this exactly:
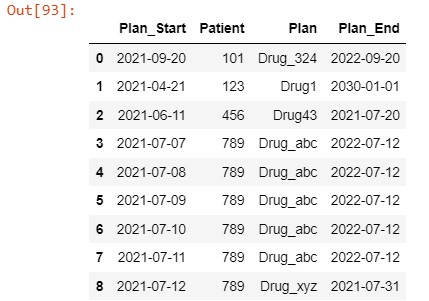
However, in the case where a Plan_Start variable may have the same date (which is often the case, as patients begin a treatment and must end it the same day bc not effective), this won't work.
tx2 = pd.DataFrame({'Patient':[123,456,789,789,789,101],
'Plan':['Drug1','Drug43','Drug_abc','Drug_xyz','Drug_123','Drug_324'],
'Plan_Start':['4/21/2021','6/11/2021','7/7/2021','7/7/2021','7/17/2021','9/20/2021'],
'Plan_End':['1/1/2030','7/20/2021','7/7/2022','7/17/2021','07/31/2021','9/20/2022']})
tx2
And this code now:
tx2.set_index('Plan_Start').groupby(['Patient']).resample('D').ffill().reset_index(level=0, drop=True).reset_index()
Now throws this error:
ValueError: cannot reindex a non-unique index with a method or limit
How can I include the duplicated row 2 (for 7/7/2021 start and end 7/7/2021), then start counting again from 7/7/2021 Plan_Start to the next Plan_Start at 7/17/2021?
CodePudding user response:
Code
mask = tx2.duplicated(['Patient', 'Plan_Start'], keep='last')
tx2_resampled = (
tx2[~mask]
.set_index('Plan_Start')
.groupby('Patient', group_keys=False)
.resample('D').ffill().reset_index()
)
tx2_result = pd.concat([tx2[mask], tx2_resampled])\
.sort_values(['Patient', 'Plan_Start'], ignore_index=True)
Logic
The core idea behind the solution is to first separate the duplicate rows by Patient and Plan_Start, then groupby and resample the non duplicate rows, finally concat the duplicates back to resampled dataframe
Result
print(tx2_result)
Patient Plan Plan_Start Plan_End
0 101 Drug_324 2021-09-20 2022-09-20
1 123 Drug1 2021-04-21 2030-01-01
2 456 Drug43 2021-06-11 2021-07-20
3 789 Drug_abc 2021-07-07 2022-07-07
4 789 Drug_xyz 2021-07-07 2021-07-17
5 789 Drug_xyz 2021-07-08 2021-07-17
6 789 Drug_xyz 2021-07-09 2021-07-17
7 789 Drug_xyz 2021-07-10 2021-07-17
8 789 Drug_xyz 2021-07-11 2021-07-17
9 789 Drug_xyz 2021-07-12 2021-07-17
10 789 Drug_xyz 2021-07-13 2021-07-17
11 789 Drug_xyz 2021-07-14 2021-07-17
12 789 Drug_xyz 2021-07-15 2021-07-17
13 789 Drug_xyz 2021-07-16 2021-07-17
14 789 Drug_123 2021-07-17 2021-07-31