I've been having trouble understanding how to make this regex more dynamic. I specifically want to pull out these for elements, but sometimes part of them will be missing. In my case here, it doesn't recognize the pattern because the 4th group isn't present.
For example, given the 2 strings:
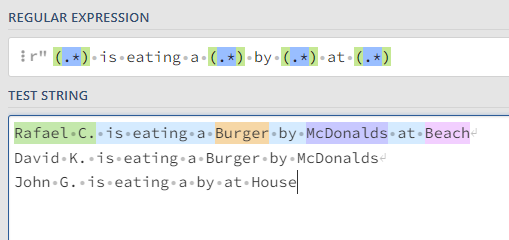
Rafael C. is eating a Burger by McDonalds at Beach
David K. is eating a Burger by McDonalds
John G. is eating a by at House
I'm trying to pull out the [name], [item], [by name], [at name]. It will always be in this patterns, but parts of it may be missing at times. Sometimes it's the name missing, sometimes it's the item, sometimes its the name and by name, etc. So I'm using:
Output desired:
I'd like it capture:
[Rafael C., Burger, McDonalds, Beach]
[David K., Burger, McDonalds, '']
[John G., '', '', 'House']
CodePudding user response:
You can use
^(.*) is eating a ((?:(?!\b(?:by|at)\b).)*?)(?: ?\bby ((?:(?!\bat\b).)*?))?(?: ?\bat (.*))?$
See the regex demo.
Details:
^- string start(.*)- Group 1: any zero or more chars other than line break chars as many as possibleis eating a- a literal string((?:(?!\b(?:by|at)\b).)*?)- Group 2: any char other than line break char, zero or more but as few as possible occurrences, that is not a starting point for abyoratwhole word char sequence(?: ?\bby ((?:(?!\bat\b).)*?))?- an optional non-capturing group that matches an optional space, word boundary,by, space and then captures into Group 3 any char other than line break char, zero or more but as few as possible occurrences, that is not a starting point for anatwhole word char sequence(?: ?\bat (.*))?- an optional non-capturing group that matches an optional space, word boundary,at, space and then captures into Group 4 any zero or more chars other than line break chars as many as possible$- string end.
CodePudding user response:
I suggest using the quantifier "?" like this.
(.*) is eating a (.*) by (.*)(?: at (.*))*
This works with your example. https://regex101.com/r/B4JbdS/1
edit : You are right @chitown88 this regex should match better. I use "[^\]" instead of ".*" to trim whitespace when there is no value. I also used "(?=)" (lookahead) and "(?<=)" (lookbehind) to capture groupe between two specific match.
(.*)(?=^is eating a| is eating a).*(?<=^is eating a| is eating a) *([^\\]*?) *(?=by).*(?<=by) *([^\\]*?) *(?=at |at$).*(?<=at |at$)(.*)