I have a dataset with a delimiter "->" like:
ROW 1- "Q -> Res -> tes -> Res -> twet"
ROW 2- "rw -> gewg -> tes -> Res -> twet"
ROW 3- "Y -> Res -> Res -> Res -> twet"
I just want to count the number of "Res" in every row
Output would be:
ROW 1- 2
ROW 2- 1
ROW 3- 3
Ive tried writing the following queries but they arnt counting correctly or only counting once:
countif(distinct(lower(FIELD_NAME) like '%Res%'))
count(split(regexp_extract(FIELD_NAME, '(.*?)Res'), '->'))
(trim(Array_reverse(split(regexp_extract(FIELD_NAME, '(.*?)Res'), '->')))
count(regexp_extract(trim(FIELD_NAME), 'Res'))
count(regexp_contains(trim(FIELD_NAME), 'Res'))
CodePudding user response:
Consider below
select id,
( select count(*)
from unnest(split(text, ' -> ')) word
where word = 'Res'
) cnt
from your_table
if applied to sample data as in your question
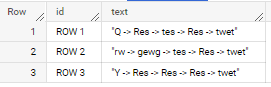
output is
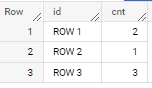
CodePudding user response:
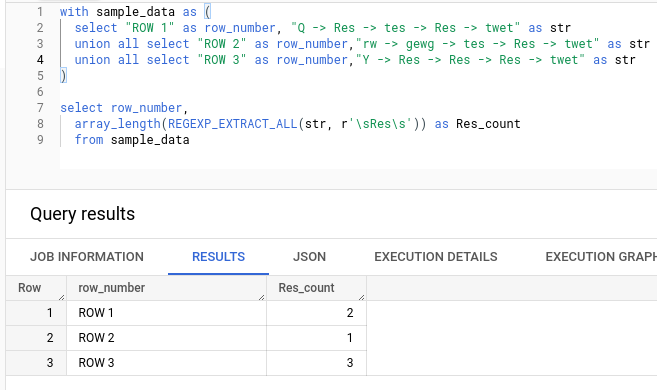
You may try and consider the below approach using REGEXP_EXTRACT_ALL():
select str,
array_length(REGEXP_EXTRACT_ALL(str, r'\sRes\s')) as Res_count
from your_table
Output:
You may refer to this documentation for more information in using this BigQuery string function.