I wanted to try to parse this nested json using Pandas, and I'm confused when i wanted to extract the data from column "amount" and "items", and the data has so many rows like hundreds, this is one of the example
{
"_id": "62eaa99b014c9bb30203e48a",
"amount": {
"product": 291000,
"shipping": 75000,
"admin_fee": 4500,
"order_voucher_deduction": 0,
"transaction_voucher_deduction": 0,
"total": 366000,
"paid": 366000
},
"status": 32,
"items": [
{
"_id": "62eaa99b014c9bb30203e48d",
"earning": 80400,
"variants": [
{
"name": "Color",
"value": "Black"
},
{
"name": "Size",
"value": "38"
}
],
"marketplace_price": 65100,
"product_price": 62000,
"reseller_price": 145500,
"product_id": 227991,
"name": "Heels",
"sku_id": 890512,
"internal_markup": 3100,
"weight": 500,
"image": "https://product-asset.s3.ap-southeast-1.amazonaws.com/1659384575578.jpeg",
"quantity": 1,
"supplier_price": 60140
}
I've tried using this and it'd only shows the index
dfjson=pd.json_normalize(datasetjson)
dfjson.head(3)
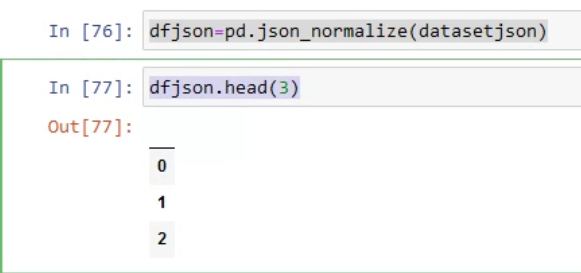
##UPDATE
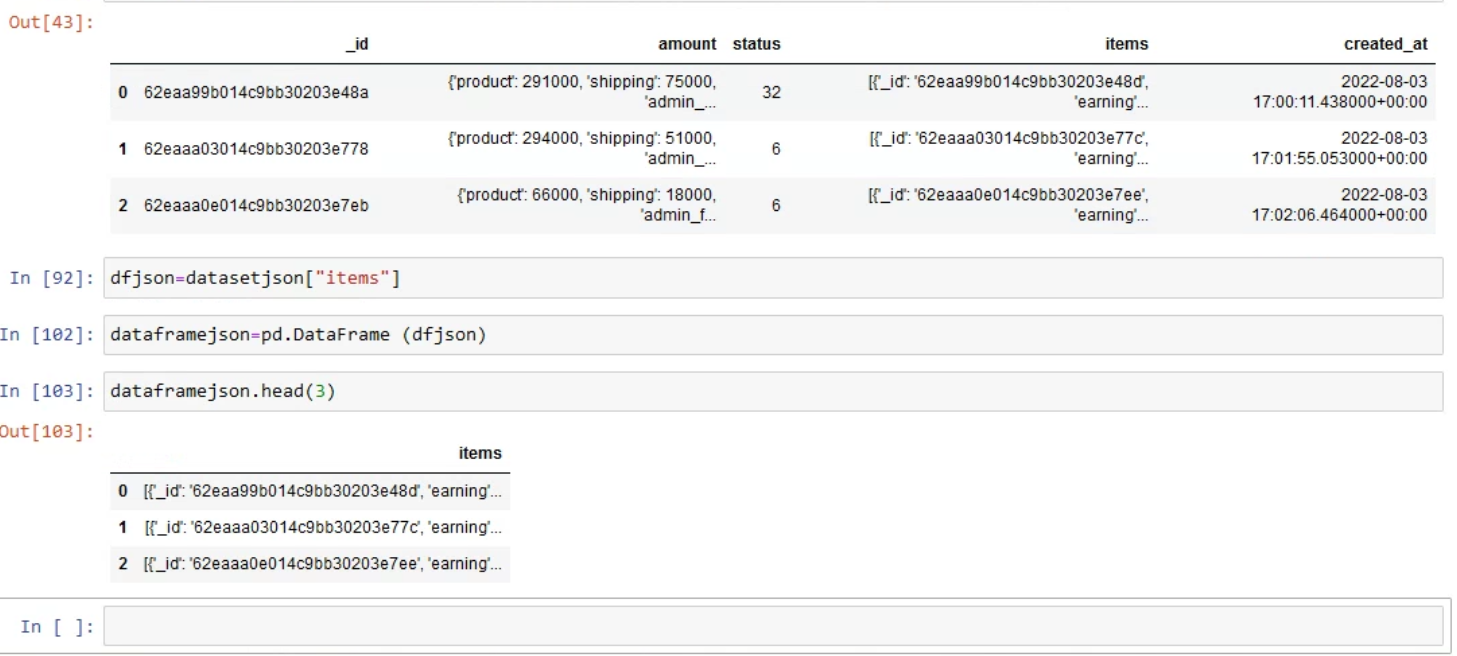
I tried added the pd.Dataframe , yes it works to become dataframe, but i still haven't got to know how to extract the _id, earning, variants
CodePudding user response:
Given:
data = {
'_id': '62eaa99b014c9bb30203e48a',
'amount': {'admin_fee': 4500,
'order_voucher_deduction': 0,
'paid': 366000,
'product': 291000,
'shipping': 75000,
'total': 366000,
'transaction_voucher_deduction': 0},
'items': [{'_id': '62eaa99b014c9bb30203e48d',
'earning': 80400,
'image': 'https://product-asset.s3.ap-southeast-1.amazonaws.com/1659384575578.jpeg',
'internal_markup': 3100,
'marketplace_price': 65100,
'name': 'Heels',
'product_id': 227991,
'product_price': 62000,
'quantity': 1,
'reseller_price': 145500,
'sku_id': 890512,
'supplier_price': 60140,
'variants': [{'name': 'Color', 'value': 'Black'},
{'name': 'Size', 'value': '38'}],
'weight': 500}],
'status': 32
}
Doing:
df = pd.json_normalize(data, ['items'], ['amount'])
df = df.join(df.amount.apply(pd.Series))
df = df.join(df.variants.apply(pd.DataFrame)[0].set_index('name').T.reset_index(drop=True))
df = df.drop(['amount', 'variants'], axis=1)
print(df)
Output:
_id earning marketplace_price product_price reseller_price product_id name sku_id internal_markup weight image quantity supplier_price product shipping admin_fee order_voucher_deduction transaction_voucher_deduction total paid Color Size
0 62eaa99b014c9bb30203e48d 80400 65100 62000 145500 227991 Heels 890512 3100 500 https://product-asset.s3.ap-southeast-1.amazon... 1 60140 291000 75000 4500 0 0 366000 366000 Black 38
There's probably a better way to do some of this, but the sample provided wasn't even a valid json object, so I can't be sure what the real data actually looks like.
CodePudding user response:
Try pd.json_normalize(datasetjson, max_level=0)
CodePudding user response:
I guess you are confuse working with dictionaries or json format.
This line is the same sample you have but it's missed ]} at the end. I formatted removing blank spaces but it's the same:
dfjson = {"_id":"62eaa99b014c9bb30203e48a","amount":{"product":291000,"shipping":75000,"admin_fee":4500,"order_voucher_deduction":0,"transaction_voucher_deduction":0,"total":366000,"paid":366000},"status":32,"items":[{"_id":"62eaa99b014c9bb30203e48d","earning":80400,"variants":[{"name":"Color","value":"Black"},{"name":"Size","value":"38"}],"marketplace_price":65100,"product_price":62000,"reseller_price":145500,"product_id":227991,"name":"Heels","sku_id":890512,"internal_markup":3100,"weight":500,"image":"https://product-asset.s3.ap-southeast-1.amazonaws.com/1659384575578.jpeg","quantity":1,"supplier_price":60140}]}
Now, if you want to call amount:
dfjson['amount']
# Output
{'product': 291000,
'shipping': 75000,
'admin_fee': 4500,
'order_voucher_deduction': 0,
'transaction_voucher_deduction': 0,
'total': 366000,
'paid': 366000}
If you want to call items:
dfjson['items']
# Output
[{'_id': '62eaa99b014c9bb30203e48d',
'earning': 80400,
'variants': [{'name': 'Color', 'value': 'Black'},
{'name': 'Size', 'value': '38'}],
'marketplace_price': 65100,
'product_price': 62000,
'reseller_price': 145500,
'product_id': 227991,
'name': 'Heels',
'sku_id': 890512,
'internal_markup': 3100,
'weight': 500,
'image': 'https://product-asset.s3.ap-southeast-1.amazonaws.com/1659384575578.jpeg',
'quantity': 1,
'supplier_price': 60140}]
For getting the items, you can create a list:
list_items = []
for i in dfjson['items']:
list_items.append(i)
CodePudding user response:
If you want to use a Dataframe, the data must be in 2d format. Your data is list,dict.. organized by data, you need to cut it first and then convert it to Dataframe.
CodePudding user response:
For how to import the entire json data into a pandas DataFrame check out the answer given by BeRT2me
but if you are only after extracting _id, earning, variants to a Pandas DataFrame giving this pandas data export to a dictionary:
{'_id' : {0: '62eaa99b014c9bb30203e48a'},
'_id_id' : {0: '62eaa99b014c9bb30203e48d'},
'earning' : {0: 80400},
'variants': {0: [{'name': 'Color', 'value': 'Black'},
{'name': 'Size', 'value': '38'}]}}
as you state in your question:
but I still haven't got to know how to extract the _id, earning, variants
notice that the problem with extracting _id, earning, variants is that this values are 'hidden" within a list of one item. Resolving this issue with indexing it by [0] gives the required values:
json_text = """\
{'_id': '62eaa99b014c9bb30203e48a',
'amount': {'admin_fee': 4500,
'order_voucher_deduction': 0,
'paid': 366000,
'product': 291000,
'shipping': 75000,
'total': 366000,
'transaction_voucher_deduction': 0},
'items': [{'_id': '62eaa99b014c9bb30203e48d',
'earning': 80400,
'image': 'https://product-asset.s3.ap-southeast-1.amazonaws.com/1659384575578.jpeg',
'internal_markup': 3100,
'marketplace_price': 65100,
'name': 'Heels',
'product_id': 227991,
'product_price': 62000,
'quantity': 1,
'reseller_price': 145500,
'sku_id': 890512,
'supplier_price': 60140,
'variants': [{'name': 'Color', 'value': 'Black'},
{'name': 'Size', 'value': '38'}],
'weight': 500}],
'status': 32}
json_dict = eval(json_text)
print(f'{(_id := json_dict["items"][0]["_id"])=}')
print(f'{(earning := json_dict["items"][0]["earning"])=}')
print(f'{(variants := json_dict["items"][0]["variants"])=}')
print('---')
print(f'{_id=}')
print(f'{earning=}')
print(f'{variants=}')
gives:
(_id := json_dict["items"][0]["_id"])='62eaa99b014c9bb30203e48d'
(earning := json_dict["items"][0]["earning"])=80400
(variants := json_dict["items"][0]["variants"])=[{'name': 'Color', 'value': 'Black'}, {'name': 'Size', 'value': '38'}]
---
_id='62eaa99b014c9bb30203e48d'
earning=80400
variants=[{'name': 'Color', 'value': 'Black'}, {'name': 'Size', 'value': '38'}]```
If you want in addition a Pandas DataFrame with rows holding all this extracted values you can loop over all your json data files adding a row to a DataFrame using:
# Create an empty DataFrame:
df = pd.DataFrame(columns=['_id', '_id_id', 'earning', 'variants'])
# Add rows to df in a loop processing the json data files:
df_to_append = pd.DataFrame(
[[json_dict['_id'], _id, earning, variants]],
columns=['_id', '_id_id', 'earning', 'variants']
)
df = df.append(df_to_append)
from pprint import pprint
pprint(df.to_dict())