I'm working with pandas for the first time and not sure if what I'm attempting is the best way to accomplish this, but I'm parsing an Excel sheet, trying to make a list of every number in a certain column (column 'C' in my case).
I returned everything from column 'C', removed the empty cells and now I'm trying to remove the '#' character that's in front of the numbers.
Here's my code from before I tried to remove the '#' character, so you can see the output:
def get_prod_cmvp_data():
prod_cmvp_data = pd.read_excel('_Request ID__Client Cryptographic Module List Template.xlsx', usecols = 'C', header = 6, )
prod_cmvp = prod_cmvp_data.dropna()
vals = prod_cmvp.values
print(vals)
output:
[['#3914']
[' #3907']
[' #3197']
['#4272']
['#4271']
['#4254']
['#3784']
['#3946']
['#3888']
['#4174']
['#4222']
['#3613']
['#3125']
['#3140']
['#3197']
[' #3196']
[' #3644']
[' #3615']
['#3651']
['#3918']
['#3946']
['#4271']
['#3888']
['#4174']
['#4222']
['#3613']
['#3125']
['#3140']]
Here's my code after I tried to remove the '#' character
def get_prod_cmvp_data():
prod_cmvp_data = pd.read_excel('_Request ID__Client Cryptographic Module List Template.xlsx', usecols = 'C', header = 6, )
prod_cmvp = prod_cmvp_data.dropna()
vals = prod_cmvp.values
values = vals.str.replace("#", "")
print(values)
Output:
AttributeError: 'numpy.ndarray' object has no attribute 'str'
Excel File:
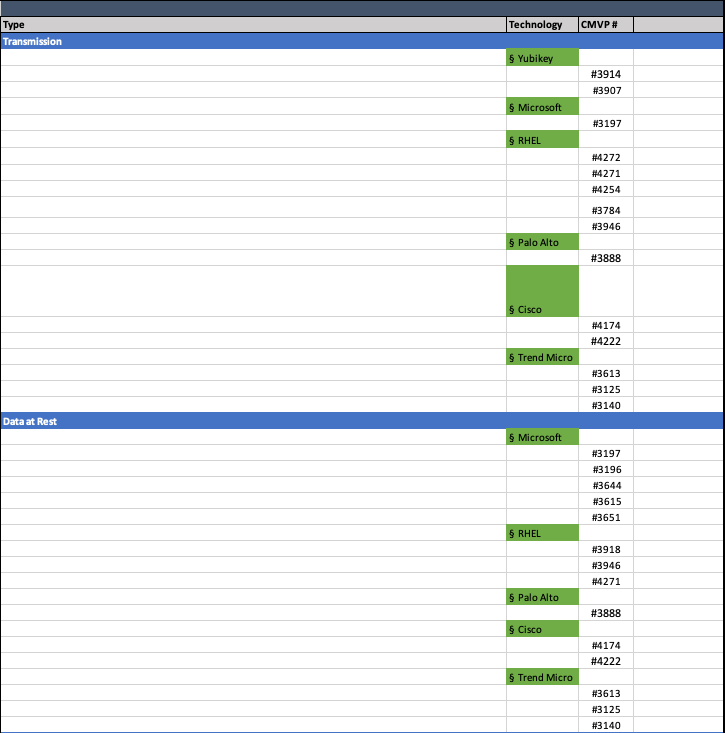
CodePudding user response:
.values returns a ndarray so won't work with .str.replace.
You should be able to drop
vals = prod_cmvp.values
And use pandas string methods on the pandas series object instead:
prod_cmvp = prod_cmvp_data.dropna()["C"].str.replace("#", "")
Caveats: From what you posted it's not easy to reproduce your input data. The solution above assumes column C holds an array of strings when read with pd. read_excel. Also, it's assumed it's called "C" otherwise replace the string '["C"]' with your correct column name. If you need to see the column names:
prod_cmvp_data.columns
CodePudding user response:
please provide excel file, it can done elegantly while reading from file. solution to current problem as below.
col=[['#3914'],
[' #3907'],
[' #3197'],
['#4272'],
['#4271'],
['#4254'],
['#3784'],
['#3946'],
['#3888'],
['#4174'],
['#4222'],
['#3613'],
['#3125'],
['#3140'],
['#3197'],
[' #3196'],
[' #3644'],
[' #3615'],
['#3651'],
['#3918'],
['#3946'],
['#4271'],
['#3888'],
['#4174'],
['#4222'],
['#3613'],
['#3125'],
['#3140']]
for i in col:
i[0]=i[0].replace('#', '')