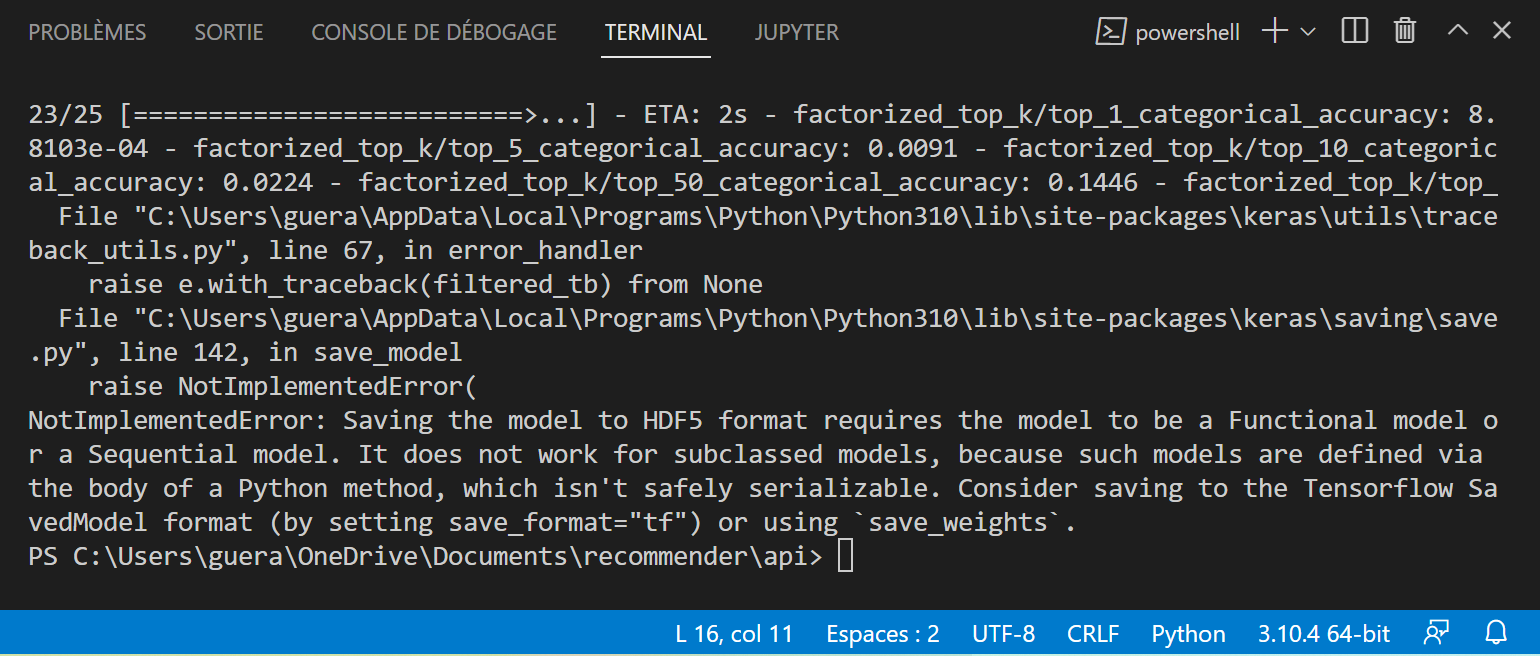
good tuto, thank you to that, but I have a problem to save model to reuse it. I have this error
File "C:\Users\guera\AppData\Local\Programs\Python\Python310\lib\site-packages\keras\utils\traceback_utils.py", line 67, in error_handler raise e.with_traceback(filtered_tb) from None File "C:\Users\guera\AppData\Local\Programs\Python\Python310\lib\site-packages\keras\saving\save.py", line 142, in save_model raise NotImplementedError(NotImplementedError: Saving the model to HDF5 format requires the model to be a Functional model or a Sequential model. It does not work for subclassed models, because such models are defined via the body of a Python method, which isn't safely serializable. Consider saving to the Tensorflow SavedModel format (by setting save_format="tf") or using
save_weights.
So how to fix them?
This my source code:
import os
import pprint
import tempfile
from typing import Dict, Text
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import joblib
import tensorflow_recommenders as tfrs
from src.models.movie_lens import MovieLensModel
def content_based_filtering(user_id, table1, table2, user_id_label, target_label):
# Ratings data.
ratings = tfds.load(table1, split="train")
# Features of all the available movies.
movies = tfds.load(table2, split="train")
# Select the basic features.
ratings = ratings.map(lambda x: {
"{}".format(target_label): x[target_label],
"{}".format(user_id_label): x[user_id_label]
})
movies = movies.map(lambda x: x[target_label])
user_ids_vocabulary = tf.keras.layers.StringLookup(mask_token=None)
user_ids_vocabulary.adapt(ratings.map(lambda x: x[user_id_label]))
movie_titles_vocabulary = tf.keras.layers.StringLookup(mask_token=None)
movie_titles_vocabulary.adapt(movies)
# Define user and movie models.
user_model = tf.keras.Sequential([
user_ids_vocabulary,
tf.keras.layers.Embedding(user_ids_vocabulary.vocab_size(), 64)
])
movie_model = tf.keras.Sequential([
movie_titles_vocabulary,
tf.keras.layers.Embedding(movie_titles_vocabulary.vocab_size(), 64)
])
# Define your objectives.
task = tfrs.tasks.Retrieval(metrics=tfrs.metrics.FactorizedTopK(
movies.batch(128).map(movie_model)
)
)
# Create a retrieval model.
model = MovieLensModel(user_model, movie_model, task)
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.5))
# Train for 3 epochs.
model.fit(ratings.batch(4096), epochs=3)
model.save('content_model.h5')
# Use brute-force search to set up retrieval using the trained representations.
index = tfrs.layers.factorized_top_k.BruteForce(model.user_model)
index.index_from_dataset(
movies.batch(100).map(lambda title: (title, model.movie_model(title))))
# Get some recommendations.
_, titles = index(np.array([str(user_id)]))
# print('Recommendation content based filtering\n')
return titles[0, :3].numpy()
The movieLensModel:
import os
import pprint
import tempfile
from typing import Dict, Text
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
class MovieLensModel(tfrs.Model):
def __init__(self, user_model, movie_model, task):
super().__init__()
self.movie_model: tf.keras.Model = movie_model
self.user_model: tf.keras.Model = user_model
self.task: tf.keras.layers.Layer = task
def compute_loss(self, features: Dict[Text, tf.Tensor], training=False) -> tf.Tensor:
# We pick out the user features and pass them into the user model.
user_embeddings = self.user_model(features["user_id"])
# And pick out the movie features and pass them into the movie model,
# getting embeddings back.
positive_movie_embeddings = self.movie_model(features["movie_title"])
# The task computes the loss and the metrics.
return self.task(user_embeddings, positive_movie_embeddings)
An image error:
CodePudding user response:
thank you for your help, the second method you give me work correctly.
model = MovieLensModel(user_model, movie_model, task)
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.5))
# Train for 3 epochs.
model.fit(ratings.batch(4096), epochs=3)
model.save_weights('content_model_weights', save_format='tf')
loaded_model = MovieLensModel(user_model, movie_model, task)
loaded_model.load_weights('content_model_weights')
result in image:
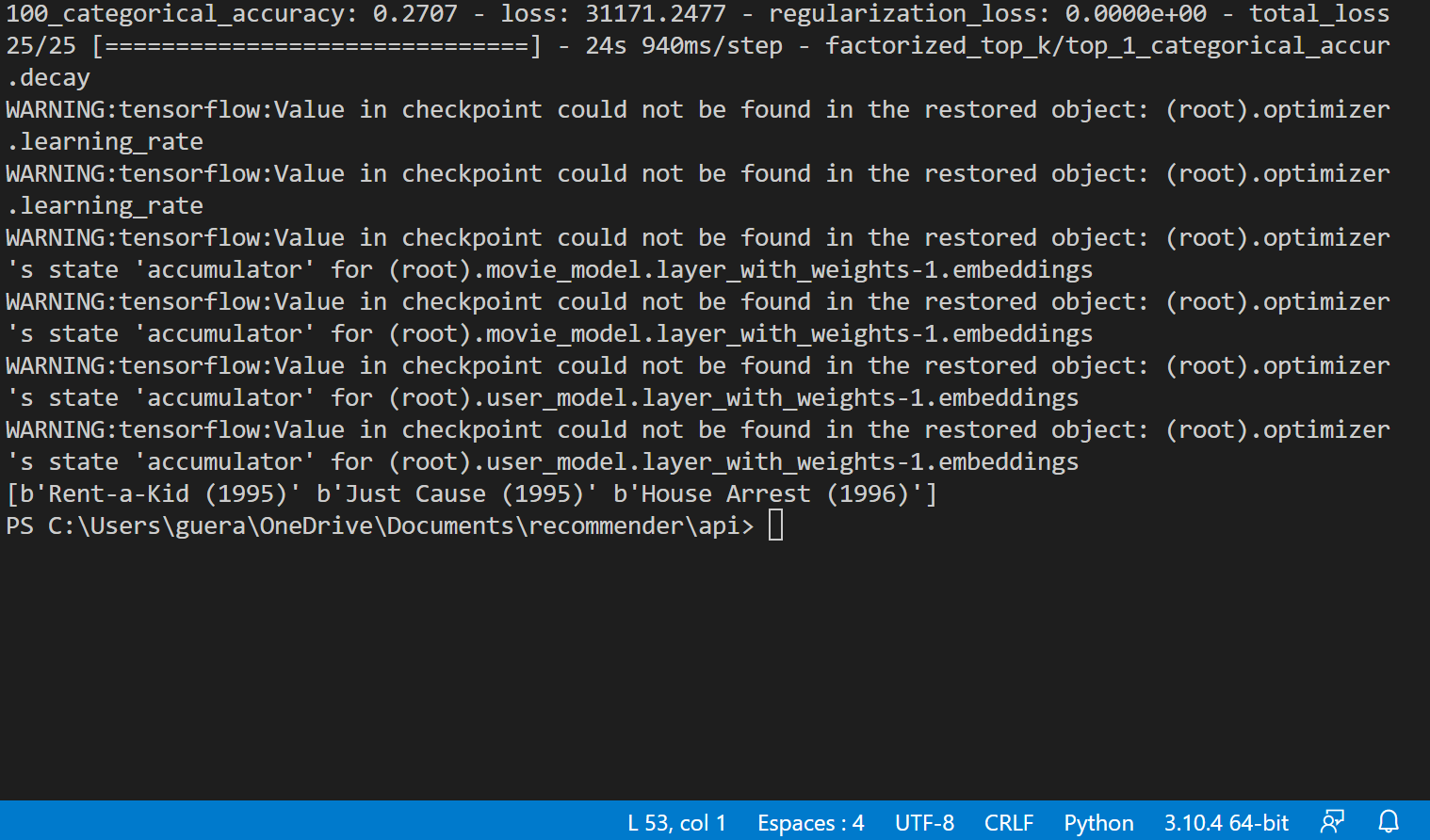
the recommendation work right, thank you so much
CodePudding user response:
Look at the error, it says:
Saving the model to HDF5 format requires the model to be a Functional model or a Sequential model. It does not work for subclassed models, because such models are defined via the body of a Python method, which isn't safely serializable. Consider saving to the Tensorflow SavedModel format (by setting save_format="tf") or using save_weights
You are experiencing this issue because of this line:
model.save('content_model.h5')
You should do as suggested, that is, save the model differently. You can follow mainly two methods.
Method 1
Try replacing that line with:
model.save("content_model", save_format='tf')
And to load it back:
loaded_model = tf.keras.models.load_model('./content_model')
Method 2
You could first save the weights like this:
model.save_weights('content_model_weights', save_format='tf')
And to load them back you need to instantiate your model object and load the weights in it:
loaded_model = MovieLensModel(user_model, movie_model, task)
loaded_model.load_weights('content_model_weights')