I'm using SparkSession.createDataFrame to create a Dataframe from a list of dict like this:
data=[
{
'id':1,
'create_time':datetime.datetime('2022','9','9','0','0','0')
},
{
'id':2,
'create_time':datetime.datetime('2022','9','9','0','0','0')
}
]
dataframe = sparkSession.createDataFrame(data)
But Spark raise an Exception:
pyspark.sql.utils.AnalysisException: cannot resolve 'create_time' given input columns
Is this because pyspark can not resolve the datetime.datetime type? How should I convert the value of 'create_time' in order to let Spark recognize this column as datetime type ?
CodePudding user response:
As the comments already mentioned: Use Integer for datetime:
data=[
{
'id':1,
'create_time':datetime.datetime(2022,9,9,0,0,0)
},
{
'id':2,
'create_time':datetime.datetime(2023,9,9,0,0,0)
}
]
dataframe = spark.createDataFrame(data)
I recommend here to follow the official documentation and use spark for the SparkSession to work on the same variable naming.
Further to your question in the 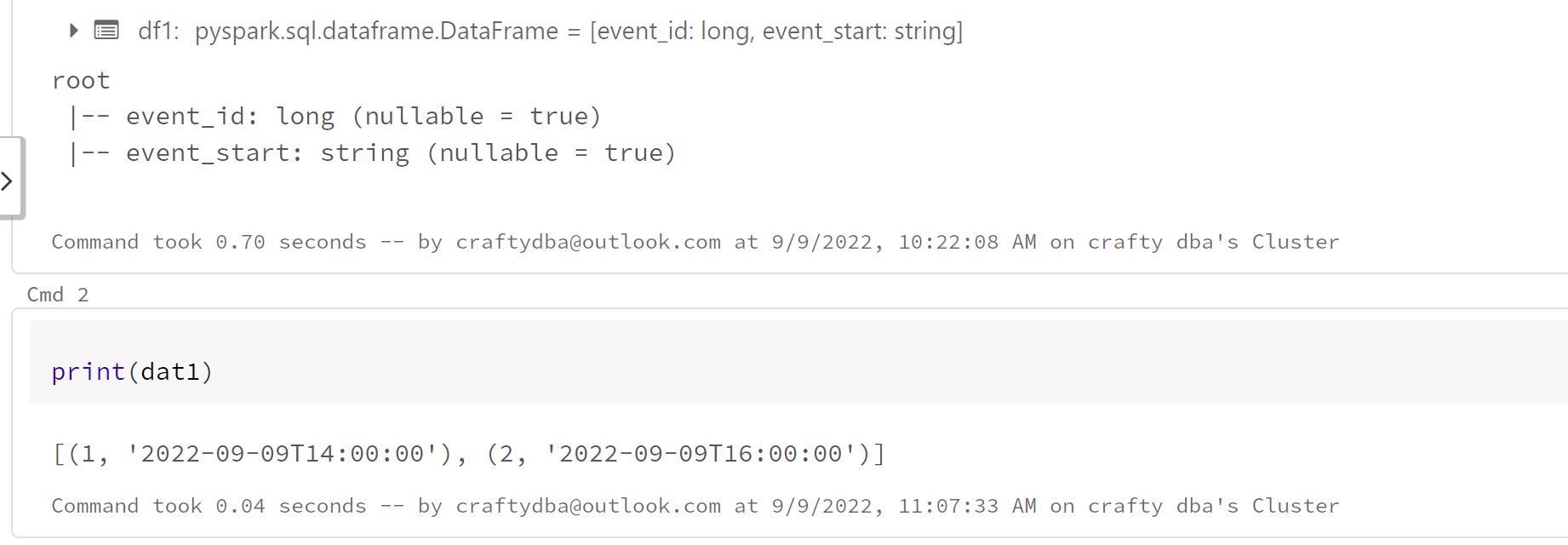
Second, we can not only change the data type within the source list but we can also supply a schema. Supplying a schema is key for large ASCII formats such as CSV, JSON, and XML. This stops the spark engine from reading the whole file to infer the data type.
#
# 2 - Create sample dataframe view
#
from datetime import datetime
from pyspark.sql.types import *
# array of tuples - data
dat2 = [
(1, datetime.strptime('2022-09-09 14:00:00', '%Y-%m-%d %H:%M:%S') ),
(2, datetime.strptime('2022-09-09 16:00:00', '%Y-%m-%d %H:%M:%S') )
]
# array of names - columns
col2 = StructType([
StructField("event_id", IntegerType(), True),
StructField("event_start", TimestampType(), True)])
# make data frame
df2 = spark.createDataFrame(data=dat2, schema=col2)
# make temp hive view
df2.createOrReplaceTempView("event_data2")
# show schema
df2.printSchema()
The image below shows we now have an integer and timestamp data types for both the list and dataframe.
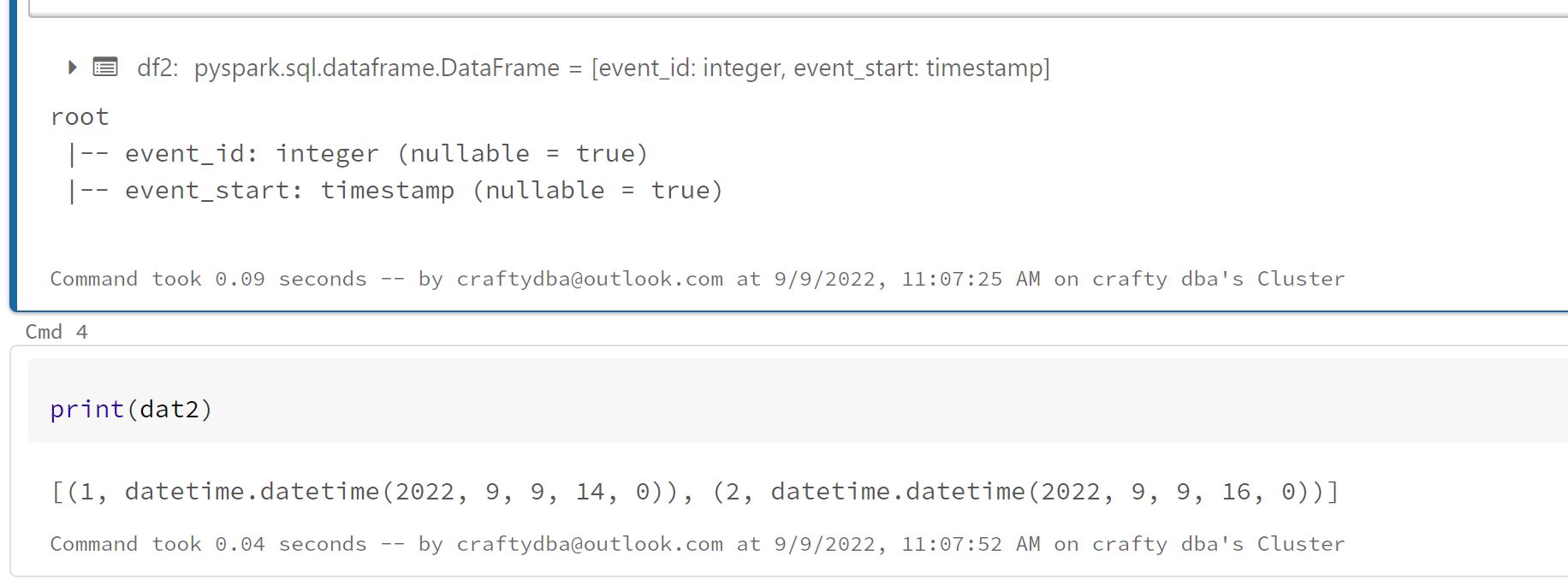
Sometimes, data is problematic in nature. Therefore, we want to import the data as a string and then apply a conversion function.
Third, the conversion of the data afterwards handles malformed data quite well.
#
# 3 - Create sample dataframe view
#
from pyspark.sql.types import StructType, StructField, IntegerType, StringType
from pyspark.sql.functions import *
# array of tuples - data
dat3 = [
# (1, '2022-09-09 14:00:00'),
(1, '2'),
(2, '2022-09-09 16:00:00')
]
# array of names - columns
col3 = StructType([
StructField("event_id", IntegerType(), True),
StructField("event_start", StringType(), True)])
# make data frame
df3 = spark.createDataFrame(data=dat3, schema=col3)
df3 = df3.withColumn("event_start", to_timestamp(col("event_start")))
# make temp hive view
df3.createOrReplaceTempView("event_data3")
# show schema
df3.printSchema()
The image below shows the date that has a year of '2' is converted to a null value since it is not valid. This malformed data will blow up the timestamp example above.
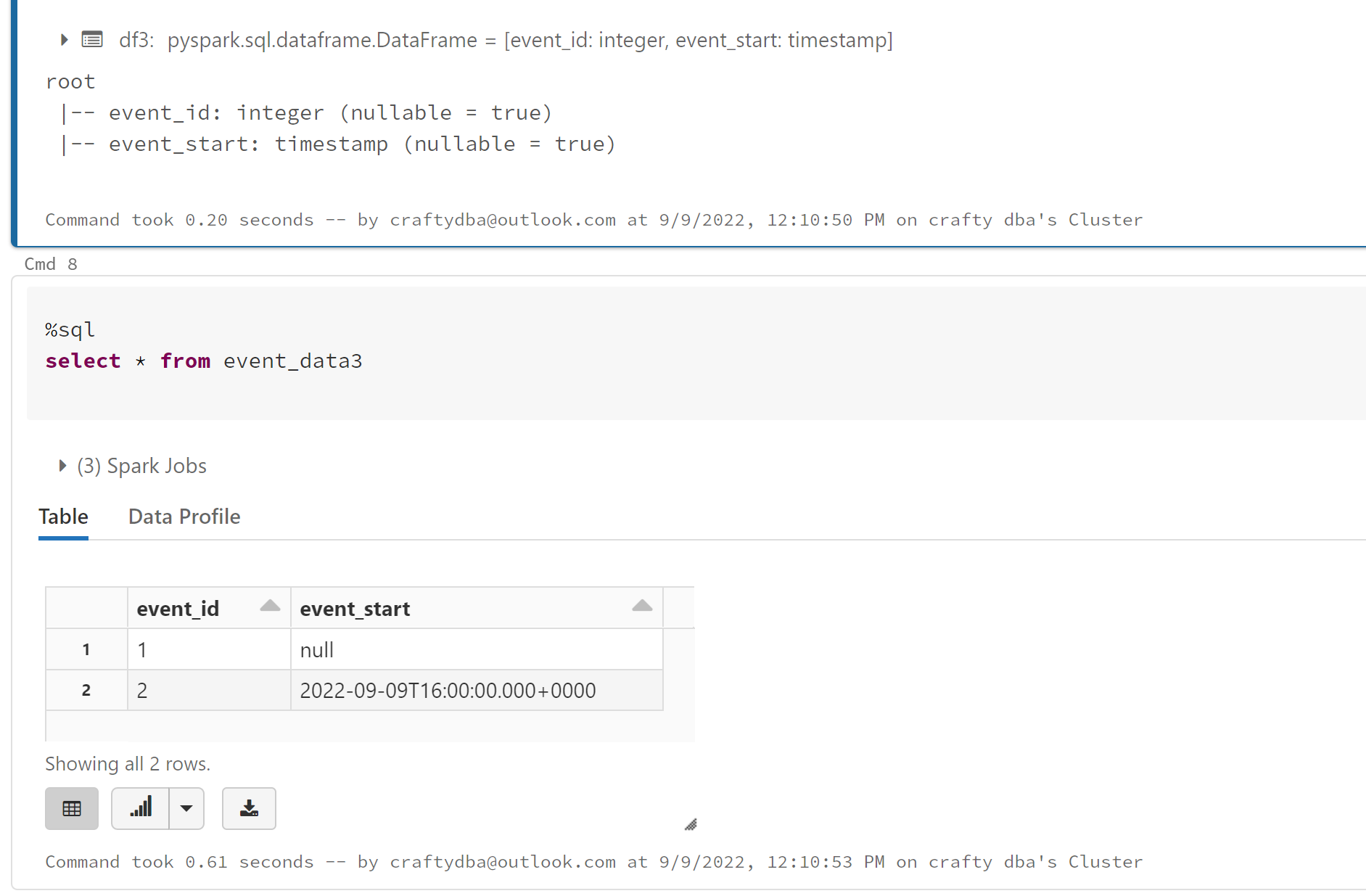
In short, know you incoming data. Profile file the data for bad values. Then determine which method is best to load the data. Always remember, supplying a schema results in a faster load time for some types of files.